
Introduction
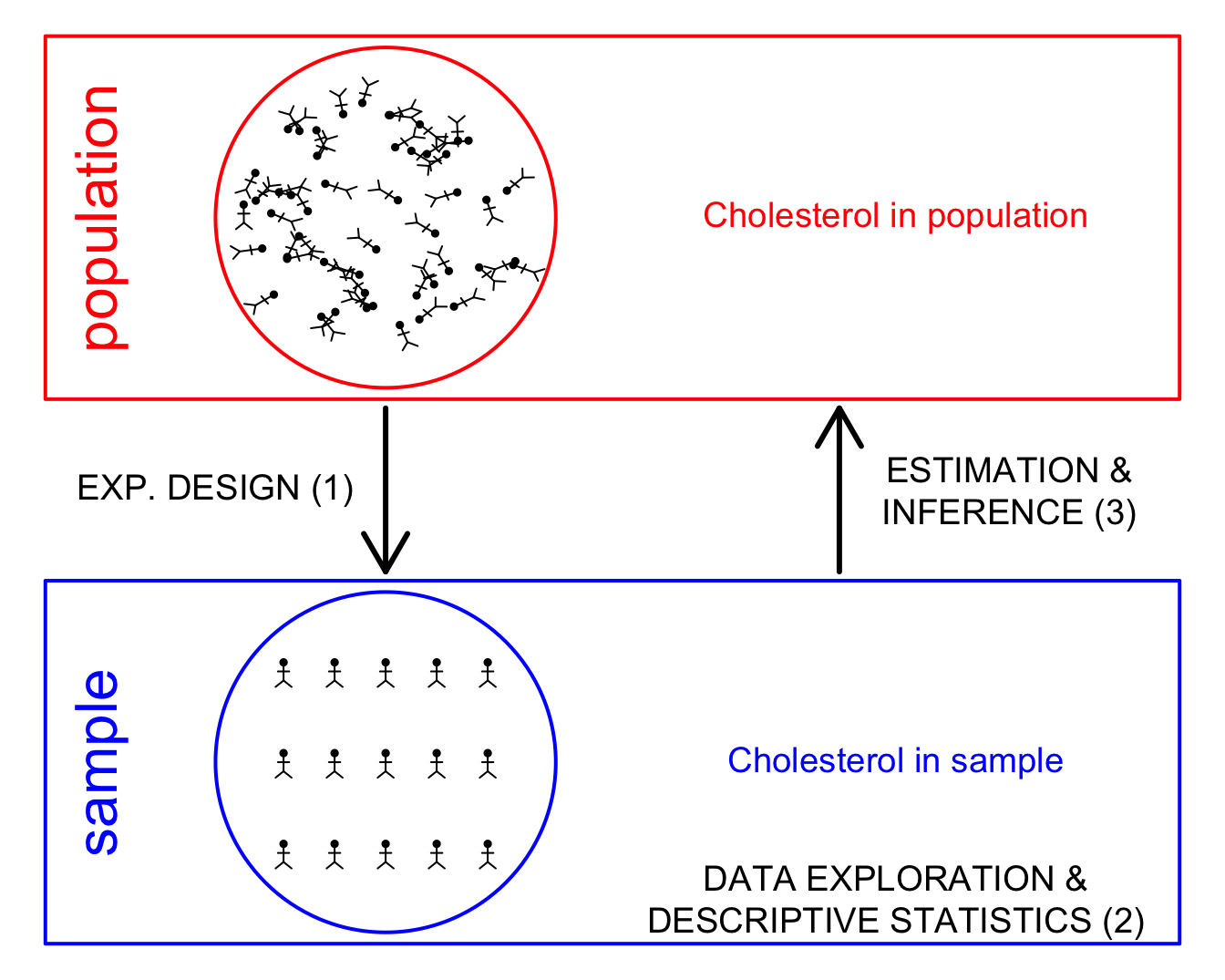
Experimental Design (1)
- Researcher determines the population to which they wants to generalize their conclusions.
- Financial and logistic limitations \(\rightarrow\) representative sample from population
Data analysis (2 & 3)
- Data-Exploration en Descriptive Statistics (2): explore, visualize, summarize, gain insight, check assumptions
- Statistical Inference (3): Generalize what we observe in the sample towards the population so that we can draw general conclusions on the biological process we study. We need statistical models to analyze the data, and, to quantify and report on variability and uncertainty.
Example
- National Health and Nutrition Examination Survey (NHANES)
- American demografic study
- Large number of physical, demographic, nutritional, life style and health characteristics
| 51624 |
male |
164.7 |
30.0_plus |
1.29 |
8 |
| 51625 |
male |
105.4 |
12.0_18.5 |
NA |
NA |
| 51630 |
female |
168.4 |
30.0_plus |
1.16 |
10 |
| 51638 |
male |
133.1 |
12.0_18.5 |
1.34 |
NA |
| 51646 |
male |
130.6 |
18.5_to_24.9 |
1.55 |
NA |
| 51647 |
female |
166.7 |
25.0_to_29.9 |
2.12 |
20 |
Variables
- We measure variables on subjects in the sample
- A Variable is a charactistic e.g. Direct cholesterol, Age, Gender,, …
- It varies from subject tot subject in the population and thus also within the sample as well as from sample to sample.
Types of variables
- Qualitative variables: a limited number of outcome categories, non-numeric.
- nominal variables: no natural ordening, e.g. gender, blood group, eye color, …
- ordinal variables: ordening, e.g. BMI class, smoking status (1: never smoked, 2: stopped smoking, 3: smoker)
- Numeric variables:
discrete variables: counts e.g. number of parners in life span, …
continuous variables: can (in theory) take each possible value between certain limits e.g. Age, Weight, BMI, fluorescence measurement in ELISA assay
Often dichotomised to turn it in a nominal qualitative variable \(\rightarrow\) information loss
Population
- Aim of scientific study: make general statements on a process at the level of the population.
- E.g. assess if the cholesterol level is on average different between males and females who are elder than 25.
\(\rightarrow\) assess cholesterol level in population above 25.
Population in statistics is a theoretical concept
- It is in continuous evolution/change
- Often interest to generalize conclusions to future subject $\rightarrow$ so population cannot be entirely observed at the present.
- Can typically be considered to be infinite.
Population has to be clearly defined!
Inclusion criteria are characteristics a subject/experimental unit must have to belong to the population, e.g.
- age above 25
- normal BMI
- …
Exclusion criteria characteristics that the subject/experimental unit is not allowed to have to belong to the population, e.g.
- pregnancy in study on new type of drug
- diabetes, history of hard drugs, low health status when the aim is to delineate a range of normal values of blood pressure in a population of healthy individuals
- …
Random Variables
Variables (e.g. direct cholesterol) vary in the population from subject to subject!
Variables are thus random because their value changes in the population.
Crucial question: How precise are the conclusions on the population based on a group of subjects in a sample!
We will thus observe differences from sample to sample.
Variability of the data plays a crucial role!
Convention
Use capital letters for a study characteristic (e.g. direct cholesterol) to indicate that it changes in the population without thinking about the observed value of a particular subject.
Variable \(X\) is a random variable and is the result of random sampling of the characteristic from the population.
Random variable \(X\) is thus the unknown variable that represent a measurement that we plan to collect on a random subject, but that we have not collected yet.
Typically a sequence of random variables \(X_1,\ldots X_n\) will be collected in the study (with n subjects or experimental units).
The concept of random variables is necessary to reason on how the results and conclusions change from sample to sample.
Random variables can be qualitative, quantitative, discrete, continuous, …
Describing the population
It is impossible to predict the value of a random variable.
The realised value of \(X\) is subject to random variability.
Suppose that we are interested in the IQ of subject. If we know how the data are distributed, we can use probability theory to calculate the probability that the IQ of a random subject of the population will be above 110.
Intermezzo probability theory
Discrete random variables
Supose that we measure a discrete random variable \(X\)
All possible values for the random variable \(X\) are called the sample space \(\Omega\).
- For gender the sample space is \(\Omega=(0,1)\) with 0 (male) or 1 (female).
- Suppose that we role a dice, then the sample space is \(\Omega=(1,2,3,4,5,6)\).
An event \(A\) is a subset of the sample space
- Get an even number when rolling a dice: \(A=(2,4,6)\).
- Can also be \(A=(1)\) one subset of the sample space.
Event space \(\mathcal{A}\) is the class of all possible events associated with a given experiment.
Two events (\(A_1\) and \(A_2\)) are multiple exclusive if they cannot occur together
- e.g. event of the odd numbers \(A_1=(1,3,5)\) and the event of getting \(A_2=(6)\)
- so \(A_1 \bigcap A_2=\emptyset\).
Probability \(P(A)\) is a function \(P: A \rightarrow [0,1]\) which satisfies
- \(P(A) \geq 0\) and \(P(A) \leq 1\) for each \(A \in \mathcal{A}\)
- \(P(\Omega)=1\)
- For multiple exclusive events \(A_1, A_2, \ldots A_k\) the probability \(P(A_1 \cup A_2 \ldots \cup A_k)= P(A_1) + \ldots + P(A_k)\)
Dice example
- odd number \(A=(1,3,5)\): this is the union of 3 multiple exclusive events \(A_1=1\), \(A_2=5\) and \(A_3=5\) so \(P(A)=P(1)+P(3)+P(5)=1/6+1/6+1/6=0.5\)
- \(\Omega=(1,2,3,4,5,6)\): \(P(\Omega)=1\)
If we draw two subjects (j and k) independently from the population then the joint probability on
\(P(X_j,X_k)= P(X_j)P(X_j)\)
Probability mass function
The probability mass function for a random variable \(X\) describes the probability of each possible value of the sample space.
Example: Gender is a binary variable (0:male, 1:female) and binary variables are Bernoulli distributed. 50.8% of the subjects of the American population are female and 49.2% are male. Let \(\pi\) be the probability on a female \(\pi=0.508\). so \[ X\sim \left \{
\begin{array}{lcl}
P(X=0) &=& 1-\pi\\
P(X=1) &=& \pi
\end{array} \right . \]
data.frame(X=c(0,1),prob=c(0.492,0.508)) %>%
ggplot(aes(x=X,xend=X,y=0,yend=prob)) +
geom_segment() +
ylab("Probability")
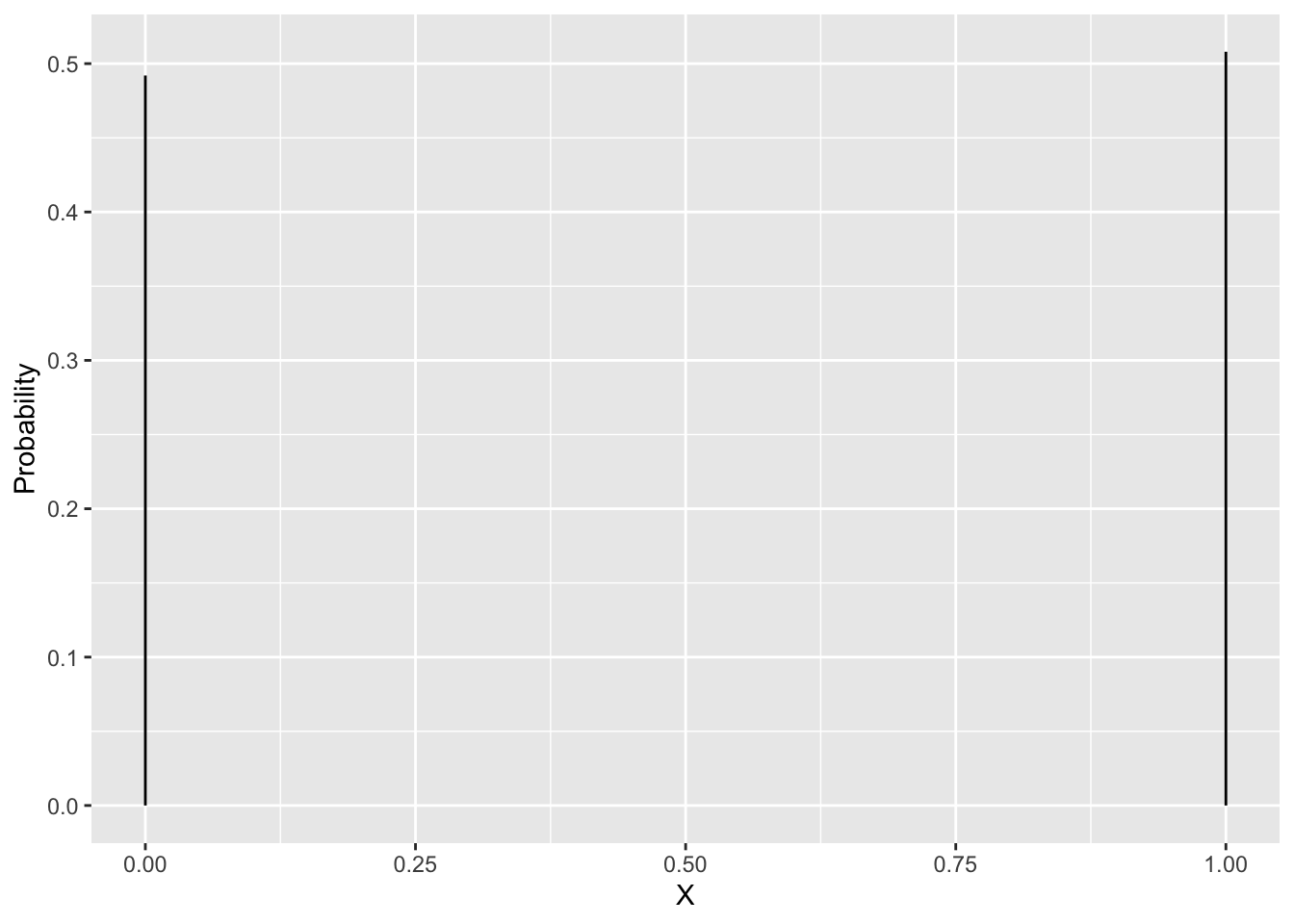
Random variable \(X\) follows an Bernoulli distribution \(B(\pi)\) with parameter \(\pi=0.508\), \[B(\pi)= \pi^x(1-\pi)^{(x-1)}\]
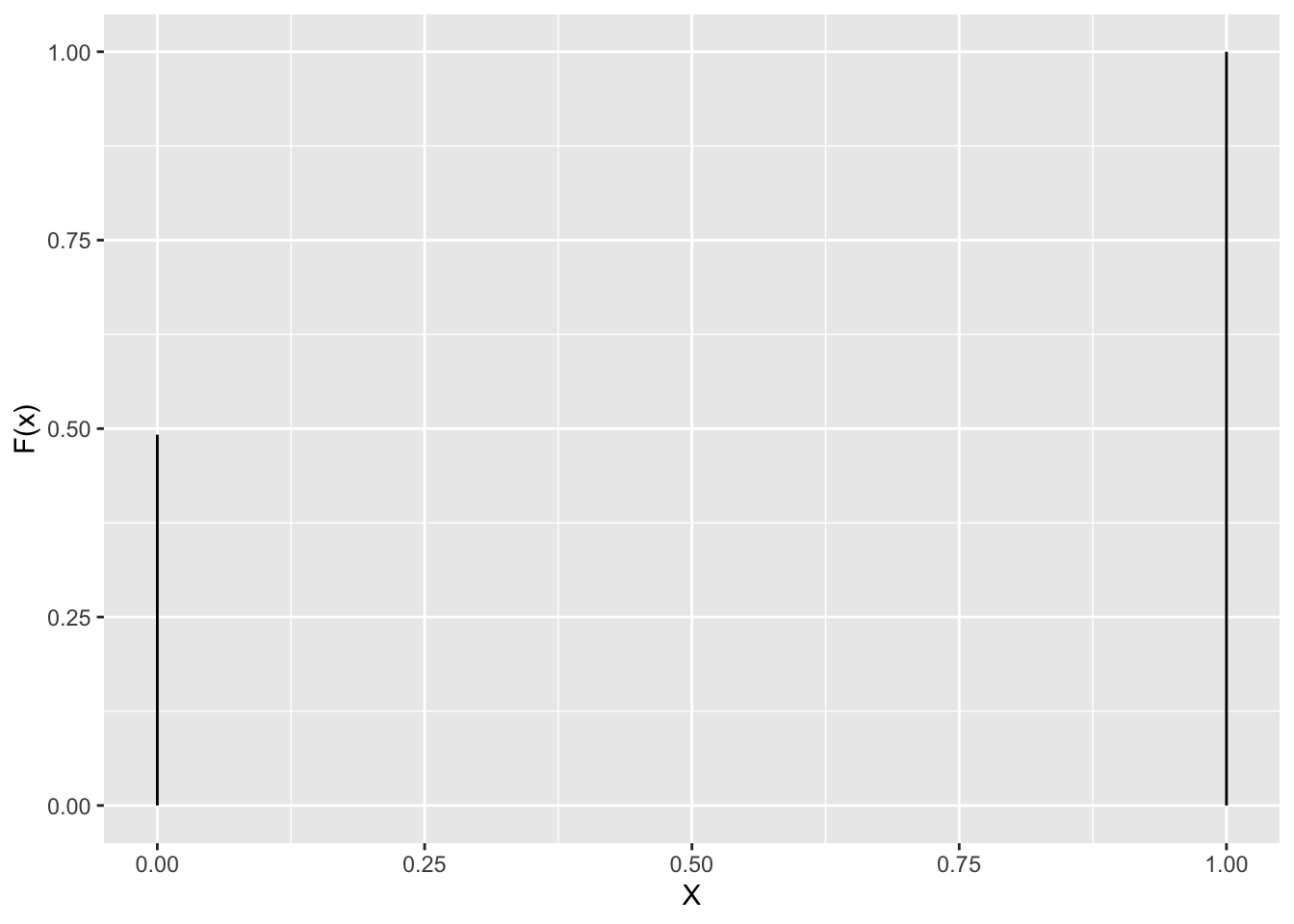
Cumulative distribution function
The cumulative distribution function is the function F(x) that calculates the probability to observe a random variable X for which \(X\leq x\): \[ F(x) = \sum\limits_{\forall X\leq x} P(x)\]
Gender example \(F(0)=1-\pi\) and F(1)=P(X=0) + P(X=1)=1
data.frame(X=c(0,1),cumprob=c(0.492,1)) %>%
ggplot(aes(x=X,xend=X,y=0,yend=cumprob)) +
geom_segment() +
ylab("F(x)")
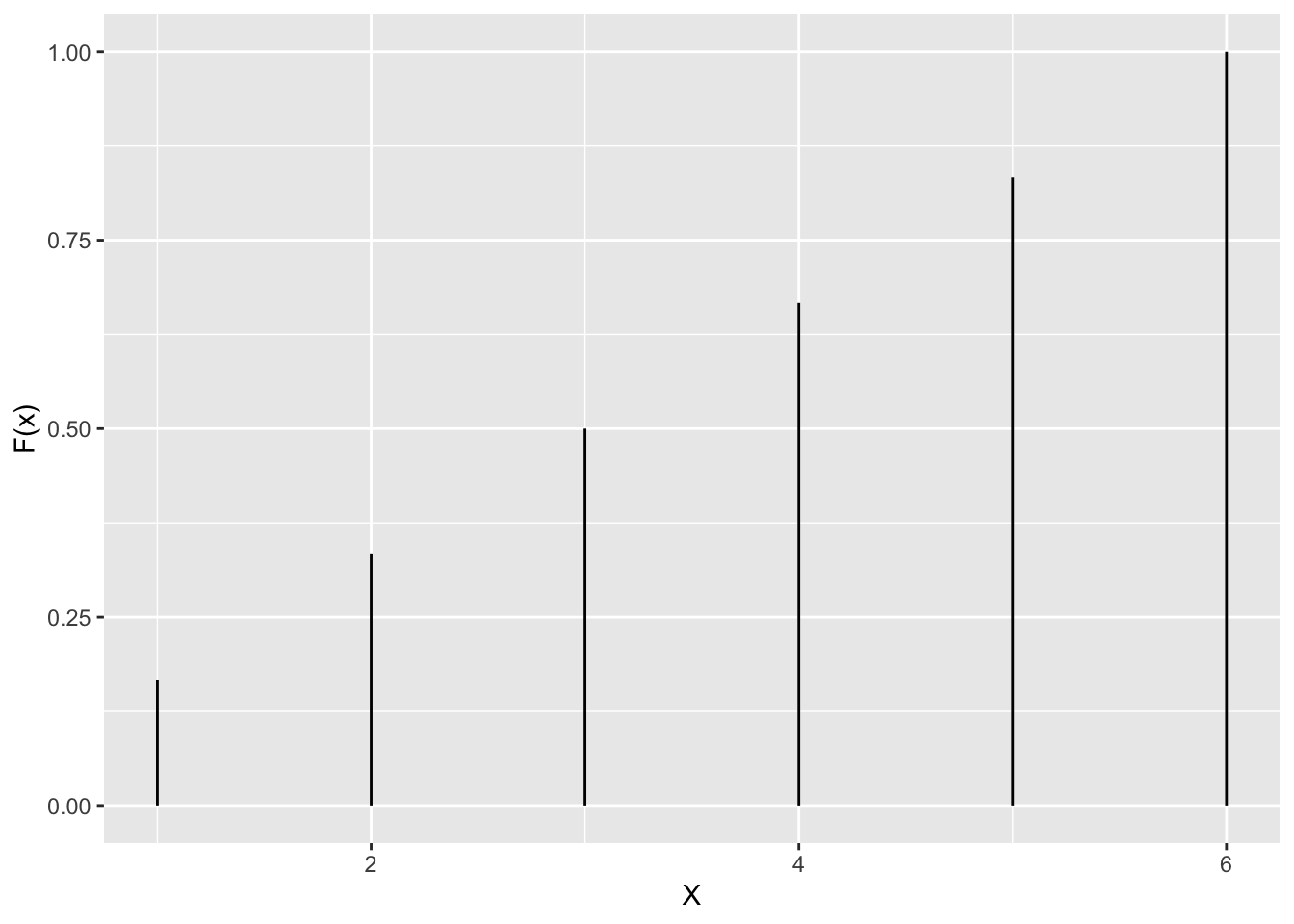
Dice:
data.frame(X=1:6,cumprob=cumsum(rep(1/6,6))) %>%
ggplot(aes(x=X,xend=X,y=rep(0,6),yend=cumprob)) +
geom_segment() +
ylab("F(x)")
Mean
The mean or the expected value \(E[X]\) of a discrete random variable is given by
\[E[X]=\sum\limits_{x\in\Omega} x P(X=x)\]
Gender example
- \(E[X]= 0 \times (1-\pi) + 1 \times \pi = \pi\)
- The mean equals \(E[X]=0.508\).
Dice example:
\[
E[X]= 1 \times 1/6 + 2 \times 1/6 + \ldots + 6 \times 1/6 = 3.5
\]
Variance
The variance is a measure for the variability of a random variable and is given by
\[E[(X-E[X])^2]=\sum\limits_{x\in\Omega} (x-E[X])^2 P(X=x)\]
- Gender example \[\begin{eqnarray}
E[(X-E[X])^2]&=&(0-\pi)^2\times (1-\pi)+(1-\pi)^2 \times \pi\\
&=& \pi^2 (1-\pi) + (1-\pi)^2 \pi\\
&=&\pi (1-\pi)(\pi+1-\pi)\\
&=&\pi(1-\pi)
\end{eqnarray}\]
Continuous random variable
The density function \(f(x)\) describes how likely it is to observe a particular value of random variable X when we sample a random subject from the population.
Many biological characteristics are approximatively normally distributed (upon transformation) \[f(x) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]
This is denoted in shorthand as \(f(x) = N(\mu,\sigma^2)\)
The IQ in the population is known to follow a normal distribution with mean \(\mu=100\) and standard deviation \(\sigma=15\).
\[IQ \sim N(100,15^2)\]
R we can use the dnorm function to calculate the density of particular values of X=x.
The arguments of dnorm are mean (\(\mu\)) and sd (standard deviation \(\sigma\)).
par(mar=c(5, 4, 4, 2) + 0.1, mai=c(1.02,0.82,0.82,0.42))
grid <- seq(40,160,.1)
plot(grid,dnorm(grid,mean=100,sd=15),
xlab="IQ",
col=2,ylab="Densiteit",type="l",lwd=2,cex.lab=1.5,cex.axis=1.5)
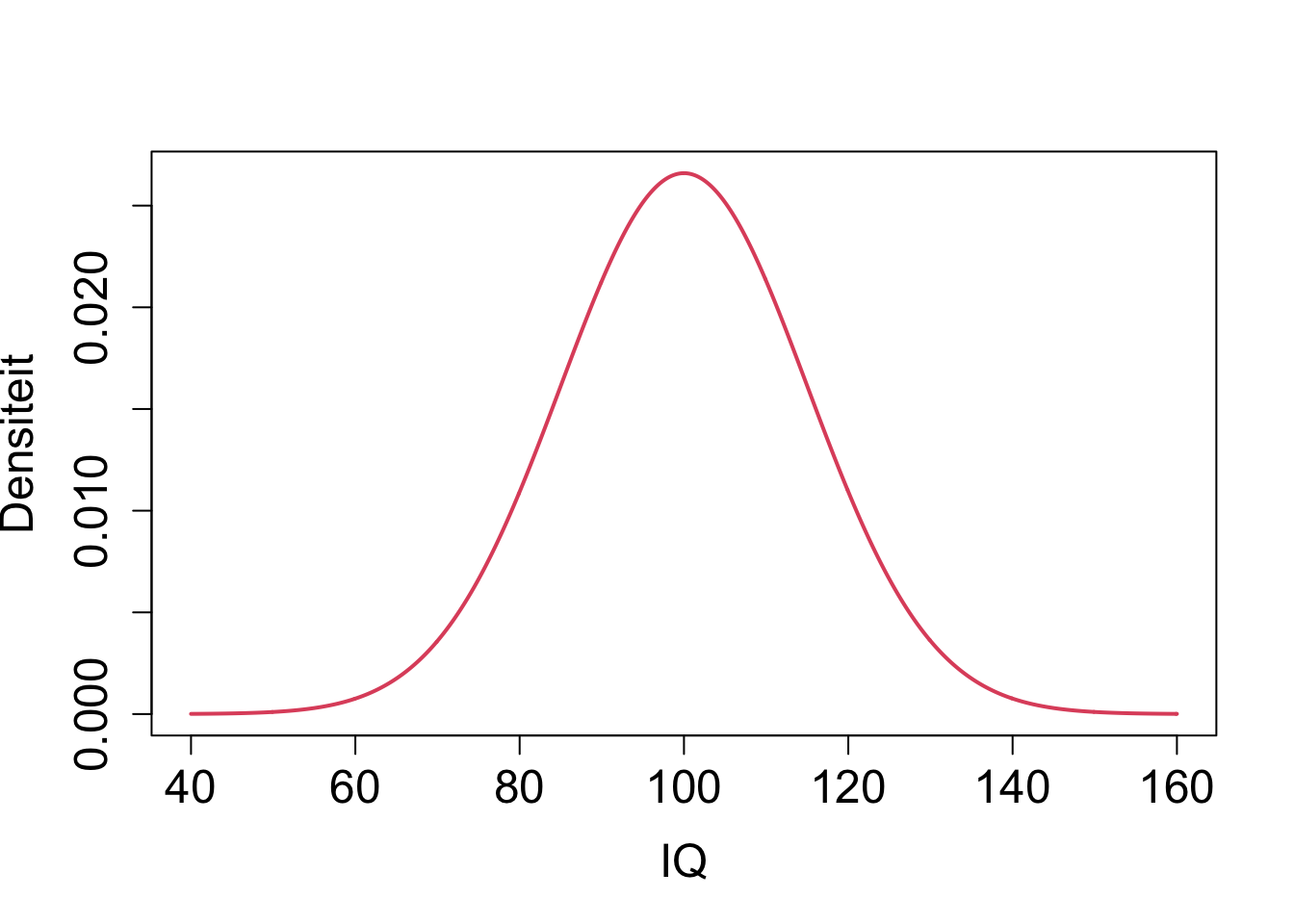
- Within certain limits, continuous variables can take all possible values so the sample space \(\Omega\) is infinitely large.
Cumulative distribution
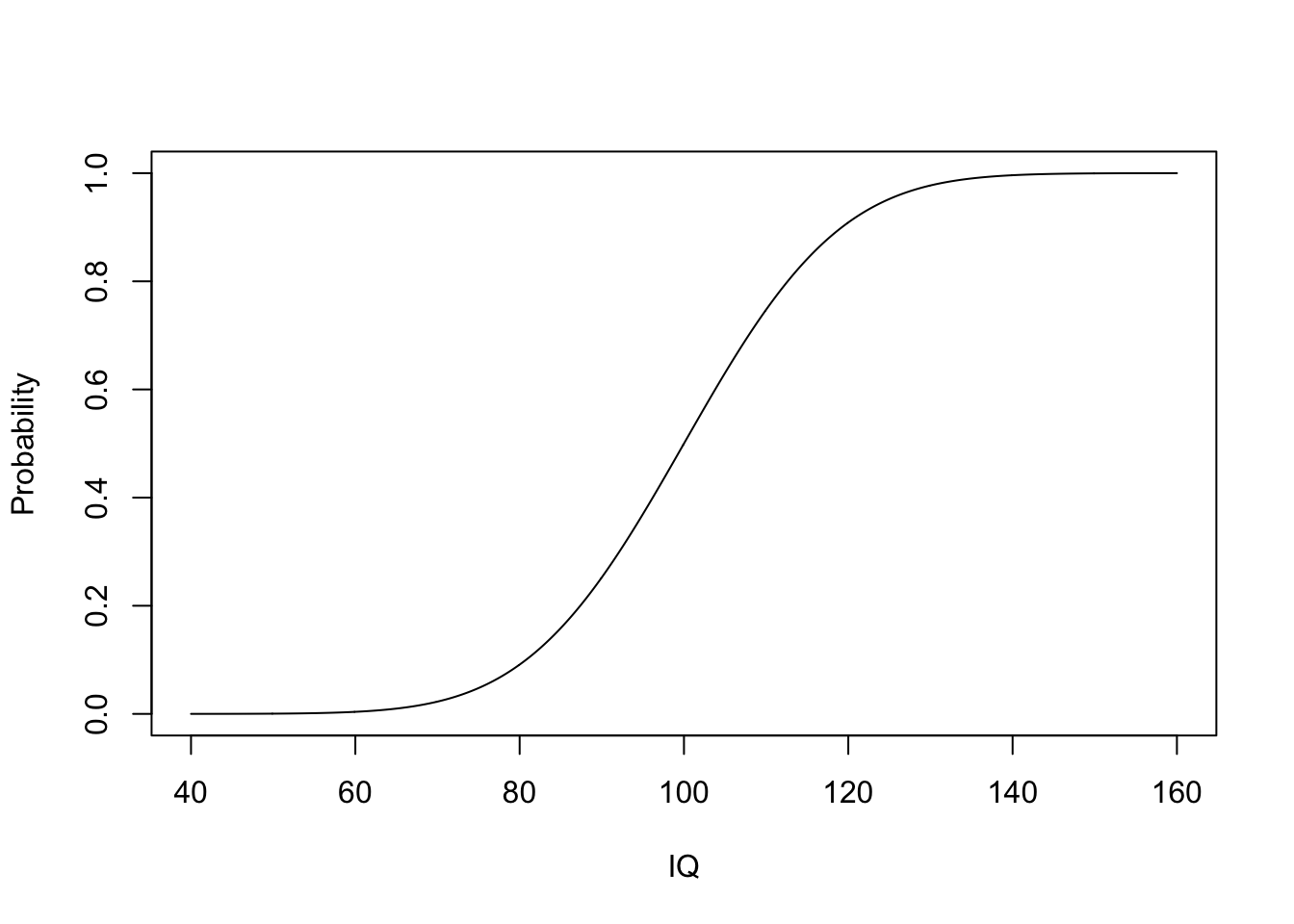
Again the cumulative distribution \(F(X)=P(X\leq x)\).
Because X is continuous we will calculate this probability using an integral \[F(x)=\int \limits_{-\infty}^x f(x) dx\]
Note that \(f(x)=0\) if x does not belong to the sample space.
We can calculate \(F(x)\) for a normally distributed random variable using the pnorm function again with arguments mean and sd.
plot(grid,pnorm(grid,mean=100,sd=15),type="l",xlab="IQ",ylab="Probability")
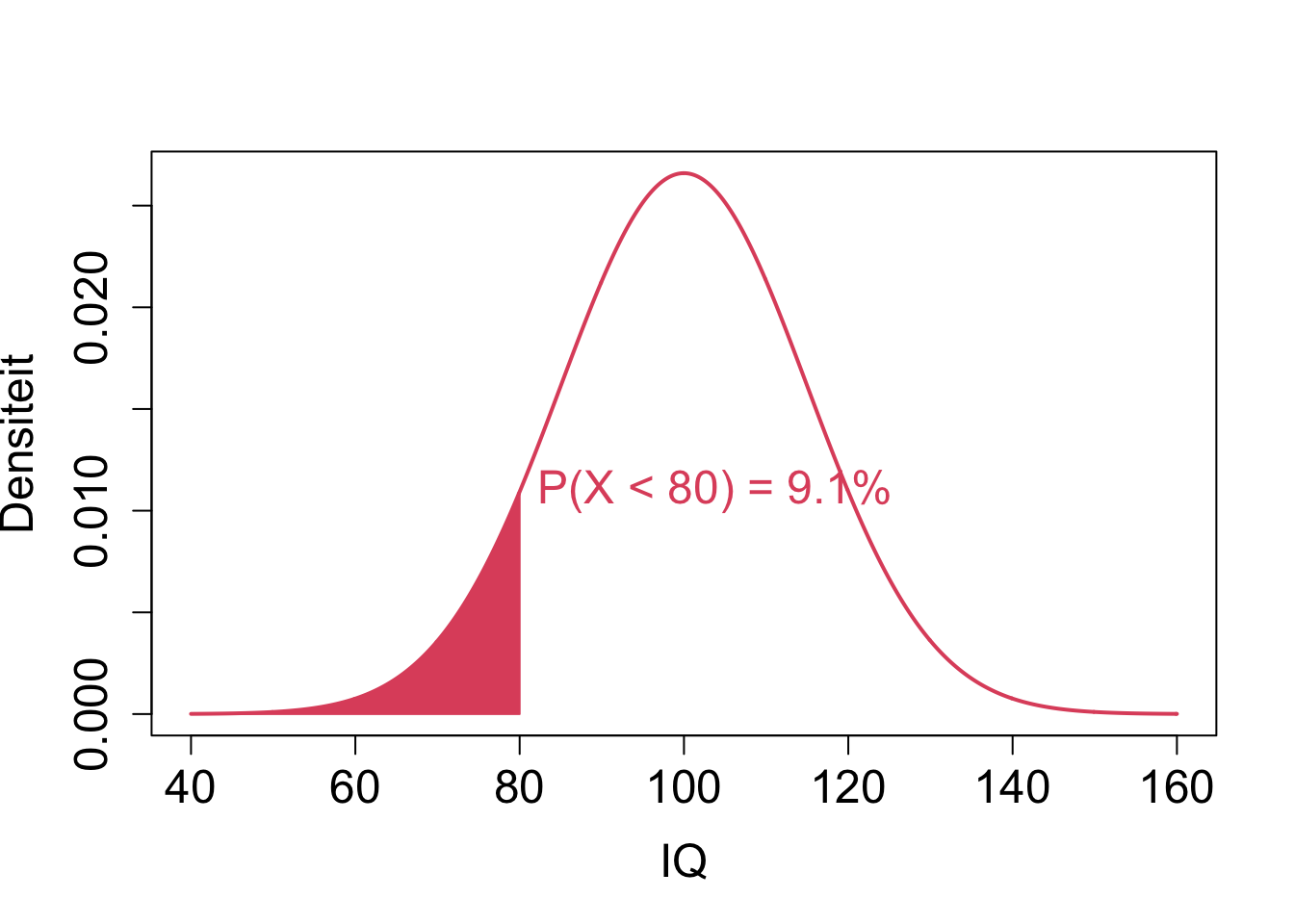
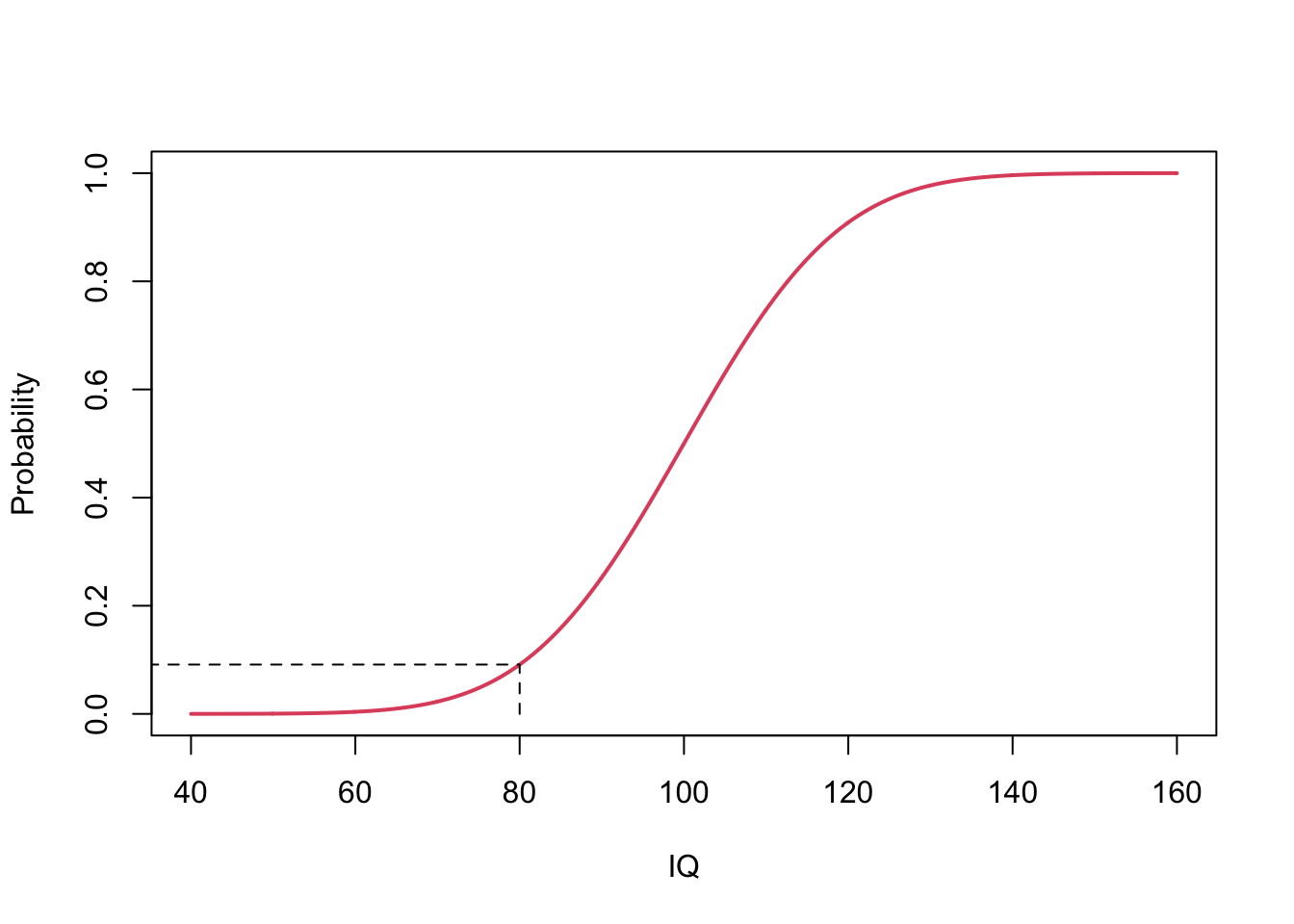
So the probability that the IQ of a random subject is below 80 can be obtained by
[1] 0.09121122
Mean and Variance.
- The mean or the expected value \(E[X]\) of a continuous random variable is given by
\[\int \limits_{x \in \Omega} x f(x) dx\]
\[\int \limits_{x \in \Omega} (x-E[X])^2 f(x) dx\]
- For the normal distribution we get
\[\int \limits_{-\infty}^{+\infty} (x-\mu)^2 f(x) dx = \sigma^2\]
- It is often difficult to interpret the variance because it is not in the same unit as the random variable and the mean. We therefore often use the standard deviation
\[SD=\sqrt{E[(X-E[X])^2]}\]
The SD for a normal distribution, \(\sigma\) has the nice interpretation that approximately 68% of the population has a value for the characteristic X within the interval of one standard deviation (\(\sigma\)) around the mean:
\[P(\mu-\sigma < X < \mu + \sigma) \approx 0.68\]
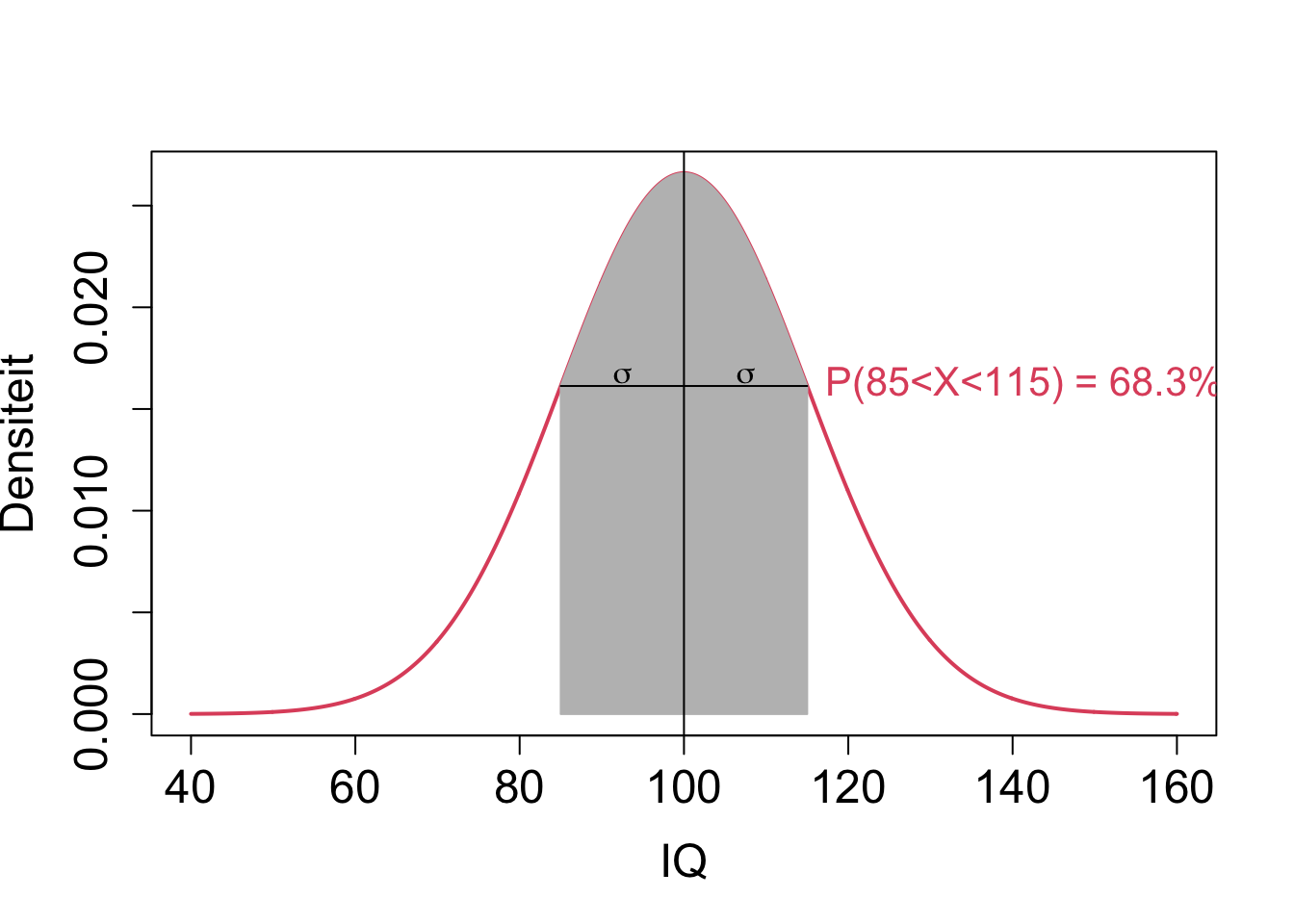
- For normally distributed random variables approximately 95% of the subjects in the population have a value that lays in two standard deviations (\(2 \sigma\)) of the mean
\[P[\mu - 2 \sigma < X < \mu + 2 \sigma]\approx 0.95\] 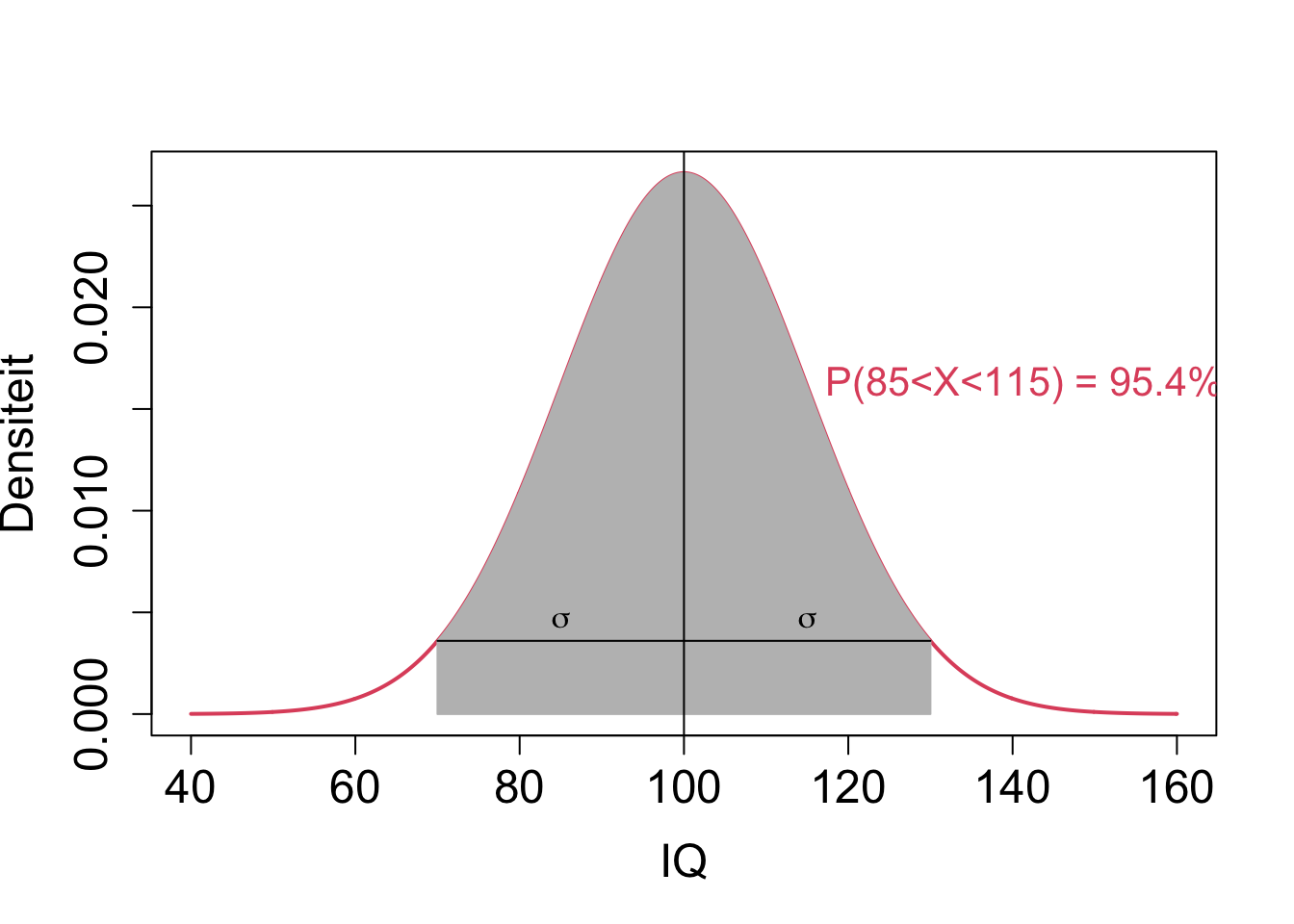
In R cumulative distribution can be calculated with the function rnorm. This function has arguments q the quantile, the mean and the standard deviation.
If you want help you can always type:
- What is the probability that a random subject in the population will have an IQ below 90?
pnorm(q=90,mean=100,sd=15)
[1] 0.2524925
Standardization
- Normal data are often standardized.
\[z=\frac{x-\mu}{\sigma}\]
- Upon standardization the data follow a standard normal distribution with mean \(\mu=0\) and variance \(\sigma^2=1\): \[z \sim N(0,1)\]
We can use the qnorm function to calculate the quantile \(z_{2.5\%}\) and \(z_{97.5\%}\) corresponding to \(F(z_{2.5\%})=0.025\) and \(F(z_{97.5\%})=0.975\), respectively.
[1] -1.959964
[1] 1.959964
This indeed indicates that about 97.5%-2.5%=95% of a standard normal random variable falls within the interval [-2,2], or within 2 times the standard deviation (\(\sigma=1\)) from the mean (\(\mu=0\)).
Sample
In real studies we typically do not know the distribution in the population.
Due to financial and logistic reasons we can almost never study the entire population.
The population parameters (e.g. mean IQ, variance of IQ) can therefore not be obtained without error.
Only as small subset of the population can be studied: the sample
Sample according to a structured design: select subject completely at random from the population so that every subject has an equal probability to end up in the sample \(\rightarrow\) Representative sample.
The sample \(x_1, x_2, . . . , x_{n}\) can be considered to be \(n\) realisations of the same random variable \(X\), for subjects \(i = 1,2,...,n\).
The distribution in the population is unknown and has to be estimated.
If we can assume that the studied characteristic follows a particular distribution (e.g. a normal distribution \(N(\mu,\sigma^2)\) then we only have to estimate the population parameters (e.g \(\mu\) and \(\sigma^2\)) based on the sample.
We refer to them as estimates and denote them by \(\hat \mu\) and \(\hat \sigma^2\).
NHANES example
Gender in the population
Select \(n=10000\) subjects at random from the American population.
Once the random individuals are sampled from the population we have observed \(n\) realisations of the random variable \(X\).
Convention: Observed values \(\rightarrow\) are denoted with a small letter \(x\).
\(x\) is a particular value measured/observed in a conducted experiment and no longer an unknown variable.
In summary
- Unknown values of the studied population characteristic for 1 to \(n\) subjects in a sample are random variables: \(X_1, \ldots, X_n\)
- We have to reason on this in order to understand how the observations, estimates and conclusions of a study can change from sample to sample.
- In a sample we observe the realised outcomes \(x_1, x_2, \dots, x_n\): e.g. the observed genders or the observed direct cholesterol levels of the subjects in the sample.
Gender Example
library(NHANES)
NHANES %>% ggplot(aes(x=Gender)) + geom_bar()
- Gender is a binary variable.
- It thus follows a Bernoulli distibution.
- The parameter of a Bernoulli distribution is the mean \(\pi\).
- We can estimate \(\pi\) based on the sample using the sample mean \(\bar x = \sum\limits_{i=1}^n x_i\)
- Note, that the sample mean is also a random variable! It also varies from sample to sample!
[1] male male male male female male
Levels: female male
- Note, that Gender is a factor and that the females are the reference class (first class).
- R by default uses the level which comes first in the alfabet as the reference class.
- We can recode the Gender using a 0 and 1 coding.
- When we use the as.numeric() function the factor Gender is transformed in a numeric value. It has two values 1 or 2. 1 stands for the first level (females) and 2 for the second level males. If we subtract 1 from it we have a 0 and 1 encoding (0 for females and 1 for males).
NHANES<-NHANES %>% mutate(gender=as.numeric(Gender)-1)
mean(NHANES$gender)
[1] 0.498
Note, that due to the encoding the sample mean is an estimate for the fraction of males in the population.
Always be careful with the encoding!
Direct cholesterol example
Empirical distribution
- We can estimate the direct cholesterol distribution of females using a histogram
NHANES %>% filter(Gender=="female") %>%
ggplot(aes(x=DirectChol)) +
geom_histogram()
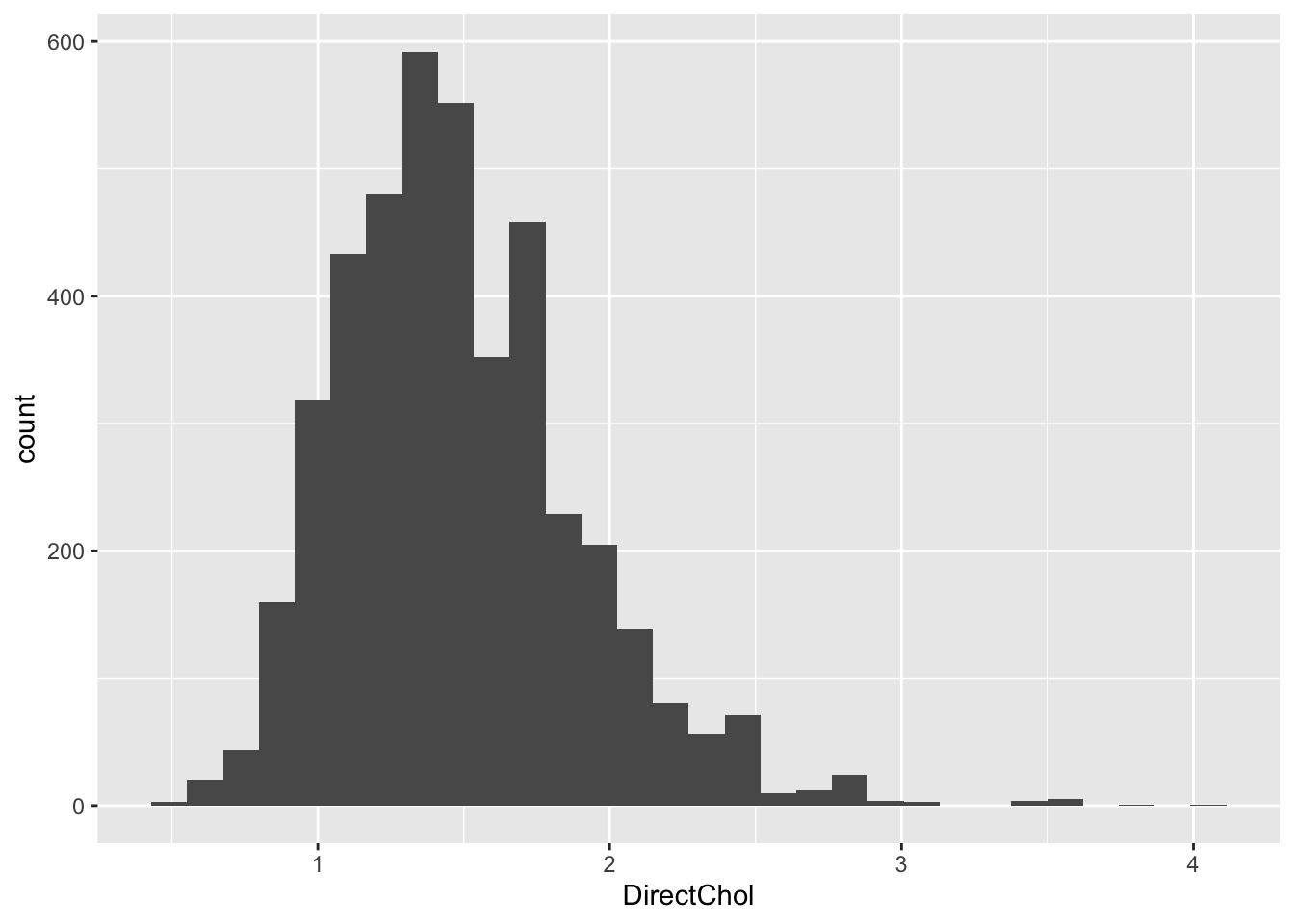
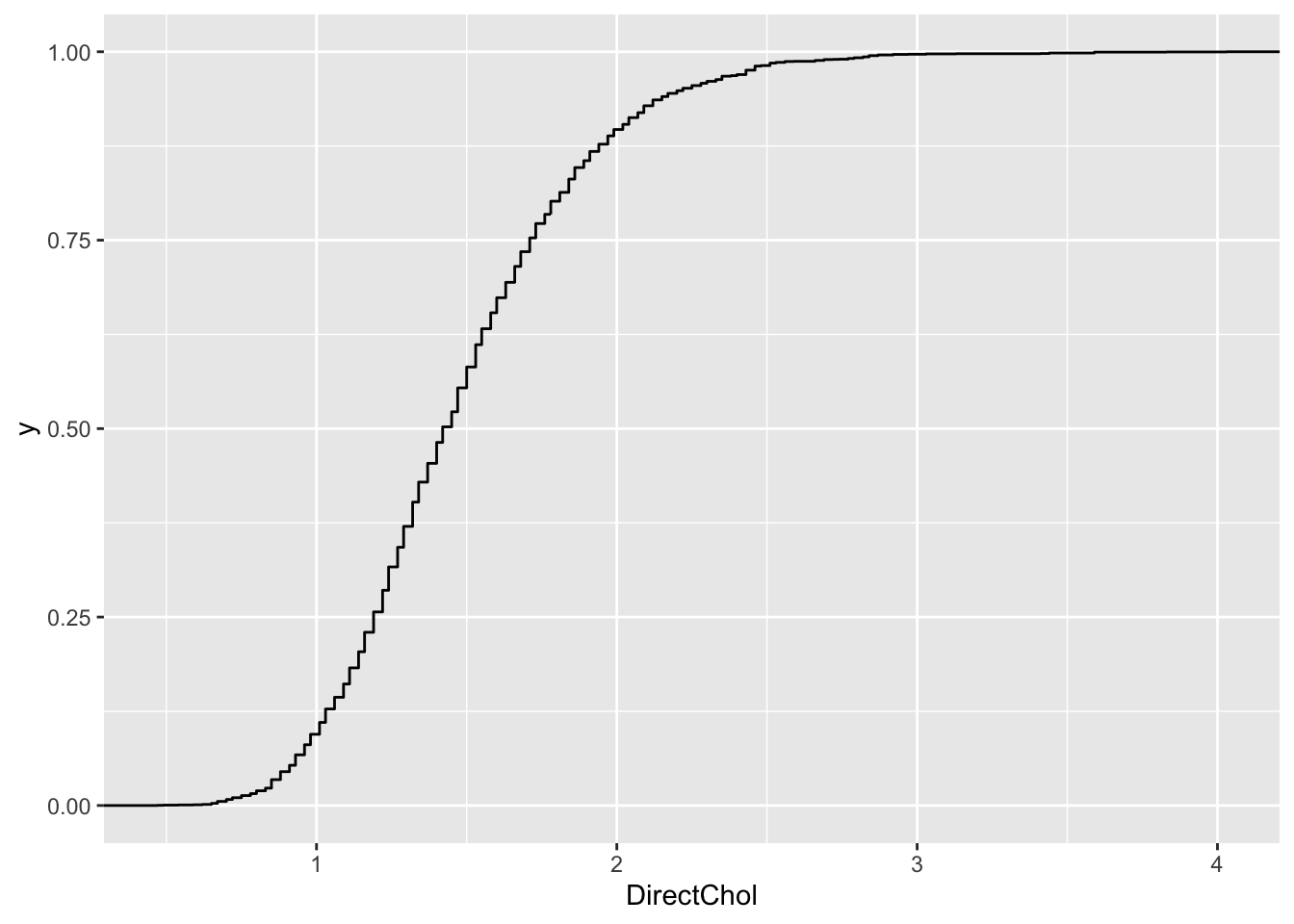
Note, that the distribution is skewed with a tail to the right.
We can estimate the cumulative distribution function using the empirical cumulative distribution function.
- Every observation in the sample is observed once.
- So the empirical distribution of the sample is a discrete distribution with probability of 1/n on every observation.
- The empirical cumulative distribution function then becomes \[ECDF(x) = \sum\limits_{x_i \leq x} \frac{1}{n} = \frac{\# (x_i \leq x)}{n}\]
fem <- NHANES %>% filter(Gender=="female"&!is.na(DirectChol))
fem %>%
ggplot(aes(x=DirectChol)) +
stat_ecdf()
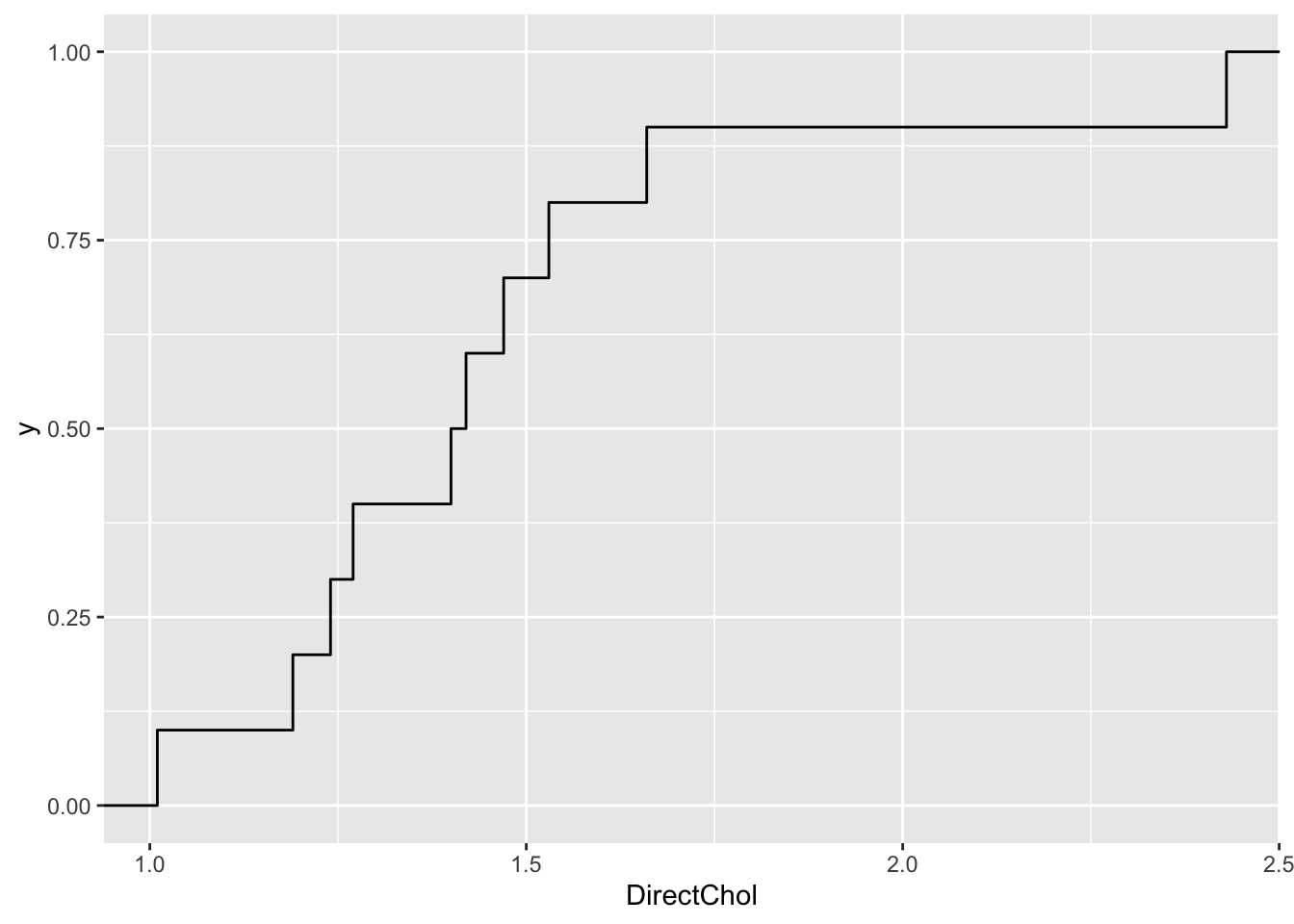
- We also illustrate this for a sample with sample size 10
set.seed(1)
fem10<- NHANES %>% filter(Gender=="female"&!is.na(DirectChol)) %>% sample_n(size=10)
fem10 %>% ggplot(aes(x=DirectChol)) +
stat_ecdf()
Normal approximation
- In the introduction we have seen that the log transformed direct cholesterol levels had a nice bell shape.
fem %>% ggplot(aes(x=DirectChol%>%log2))+
geom_histogram(aes(y=..density.., fill=..count..)) +
xlab("Direct Cholesterol (log2)") +
stat_function(fun=dnorm,color="red",args=list(mean=mean(fem$DirectChol%>%log2), sd=sd(fem$DirectChol%>%log2)))
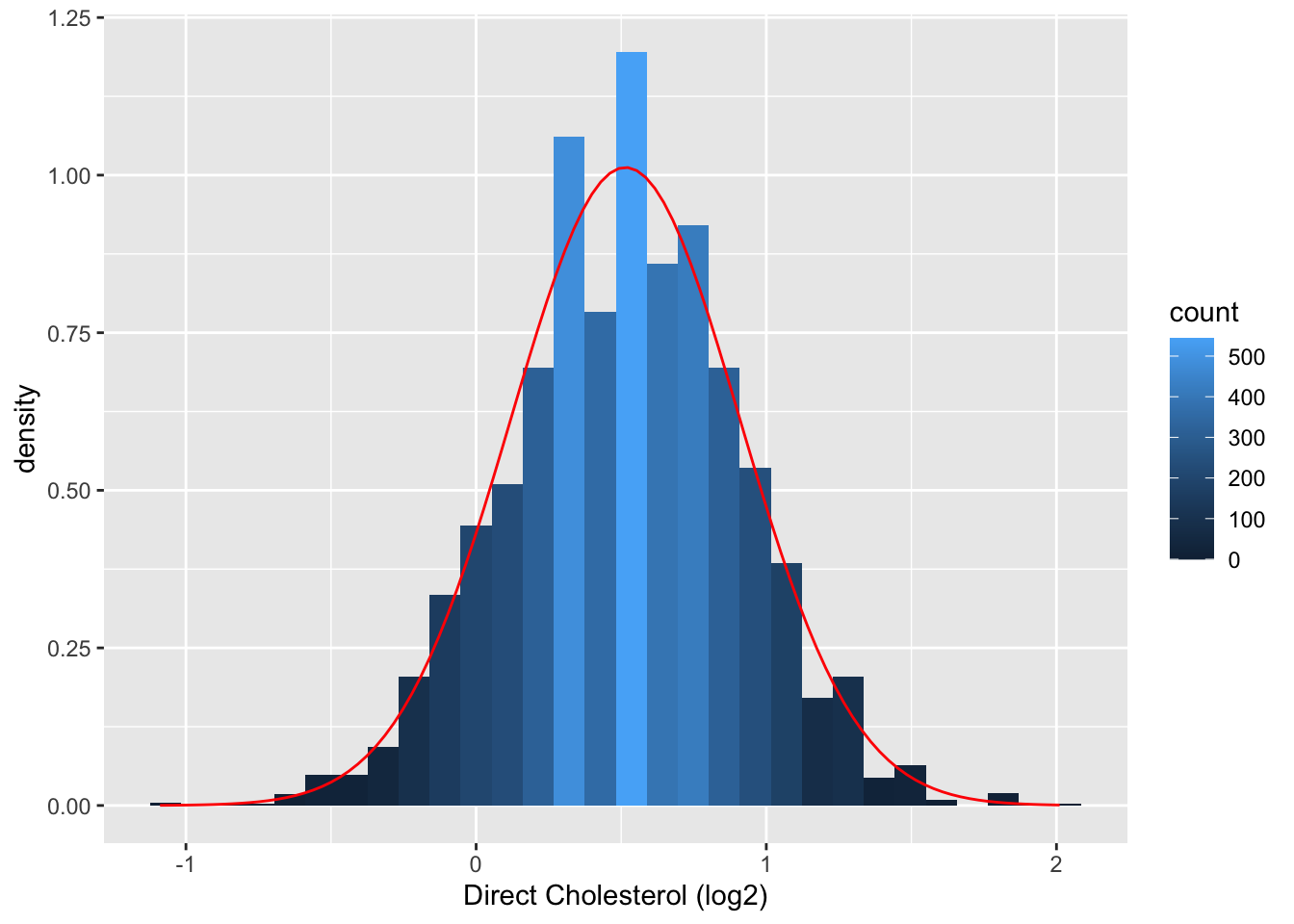
We can now approximate the distribution of log2 transformed direct cholesterol levels using a normal distribution.
We only have to estimate two parameters: the mean and the variance. We can do this based on the sample mean (\(\bar x\)) and sample variance (\(s^2\)) or sample standard deviation (\(s\)).
xBar<-mean(fem$DirectChol%>%log2)
sdBar<-sd(fem$DirectChol%>%log2)
xBar
[1] 0.5142563
[1] 0.394117
- We can do the same thing for the small sample with 10 women.
fem10 %>% ggplot(aes(x=DirectChol%>%log2))+
geom_histogram(aes(y=..density.., fill=..count..),bins=10) +
xlab("Direct Cholesterol (log2)") +
stat_function(fun=dnorm,color="red",args=list(mean=mean(fem10$DirectChol%>%log2), sd=sd(fem10$DirectChol%>%log2))) +
xlim(-2,2)
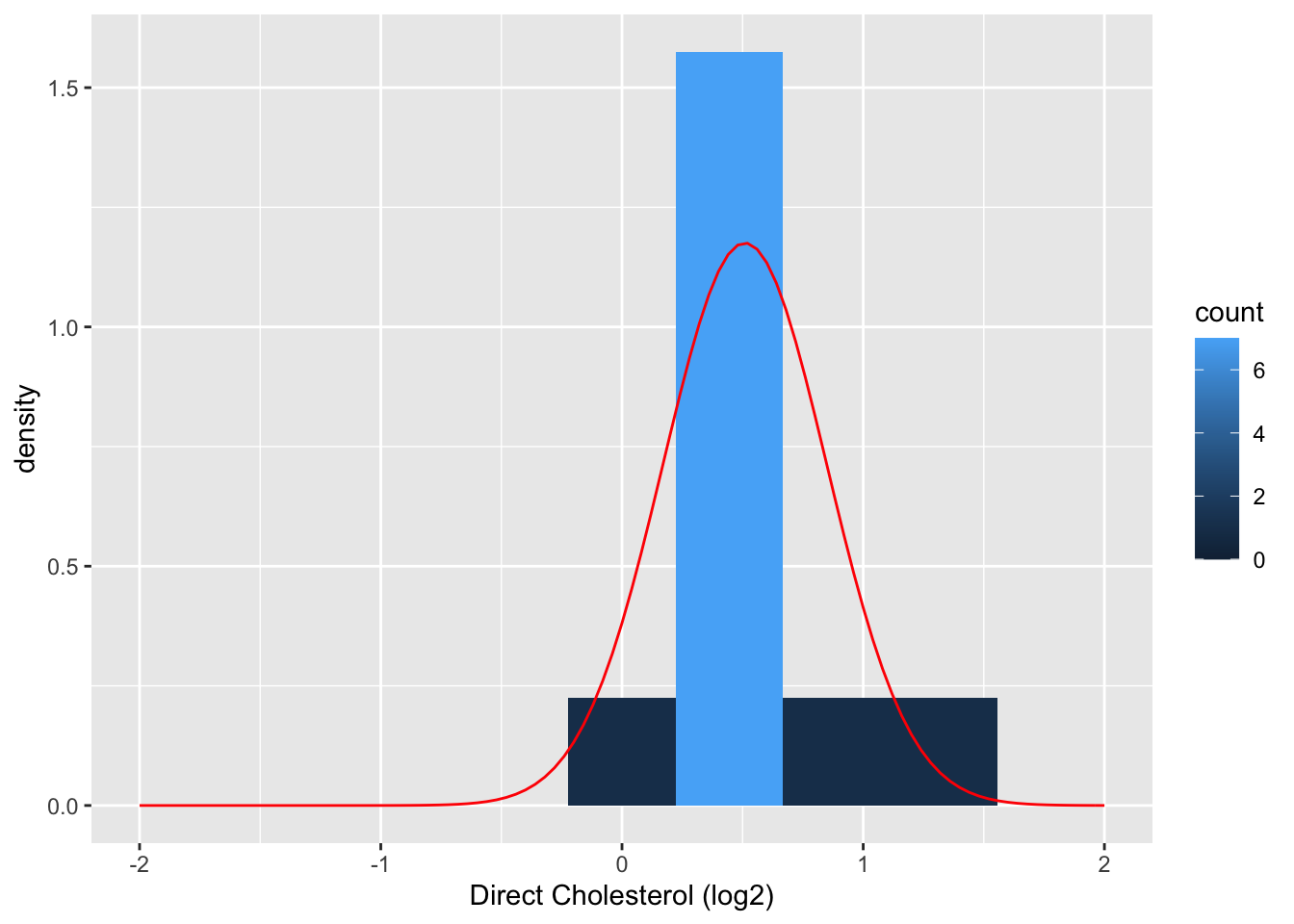
xBar10<-mean(fem10$DirectChol%>%log2)
sdBar10<-sd(fem10$DirectChol%>%log2)
xBar10
[1] 0.5093291
[1] 0.3393851
Reference intervals
Normal values for the cholesterol levels in the population can be calculated using a reference interval. Typically a 95% reference interval is used, so that 95% of the subjects in the population are expected to have a value for the characteristic that falls into the reference interval.
We can do this based on the empirical distribution using the quantile function. We need to calculate the quantiles \(\hat{F}(x_{2.5\%})=0.025\) and \(\hat{F}(x_{97.5\%})=0.975\) so that 95% of the values are located in the interval [\(x_{2.5\%}\), \(x_{97.5\%}\)] .
Large sample
quantile(fem$DirectChol,prob=c(0.025,0.975))
2.5% 97.5%
0.85 2.43
quantile(fem10$DirectChol,prob=c(0.025,0.975))
2.5% 97.5%
1.05050 2.25675
- Note, that this estimate is very crude. In the small sample, We do not have enough observations to have a good approximation of the extreme quantiles.
Normal approximation
We can use the function qnorm to calculate quantiles from the normal distribution.
We also know that a 95% reference interval is located rougly in two standard deviations around the mean.
We will have to use the function 2^ to transform the result back to the direct cholesterol domain.
Large sample
qnorm(0.025,mean=xBar,sd=sdBar) %>% 2^.
[1] 0.8361311
qnorm(0.975,mean=xBar,sd=sdBar) %>% 2^.
[1] 2.439713
[1] 0.8270361
[1] 2.466543
qnorm(0.025,mean=xBar10,sd=sdBar10) %>% 2^.
[1] 0.8976012
qnorm(0.975,mean=xBar10,sd=sdBar10) %>% 2^.
[1] 2.257165
[1] 0.8891871
[1] 2.278523
Conclusions
For the large sample, the empirical distribution (quantile function) and the normal approximation gives us approximately the same result.
For the small sample, however, the normal approximation works much better than the one based on the empirical distribution.
- This is because we are looking at extreme quantiles 2.5% and 97.5%.
- Indeed, we have very few observations at our disposal in the small sample to estimate these quantiles directly from the observations.
- With the normal approximation we can use all the data to estimate the mean and the variance. So if the normal assumption holds, we get better estimates for these extreme quantiles.
Statistics
Formula will be used to estimate the parameters of a distribution in the population based on the sample. We call these statistics or estimators.
The numeric result obtained by evaluating these formula are also called statistics or estimates.
Researcher want to known the unknown parameters from the population and will thus estimate them using the statistics observed or calculated based on the sample
Because we calculate the statistics based on the observations in the sample, they will also vary from sample to sample and are random variables and we denote them with capital letters (e.g. \(\bar X\) for the sample mean and \(S^2\) for the sample variance).
So when we analyse data, we have to reason on how the statistics of interest will vary from sample to sample.
When the statistics refer to a numeric value realised in a particular sample, we will use a small letter: \(\bar x\) and \(s^2\).
Convention
Population parameters are fixed but unknown and we will denote them with \(\rightarrow\) Greek symbols.
Statistics that we use to estimate unknown parameters based on the sample are denoted with letters are with a hat.
e.g. for normal distribution
| \(\mu\) |
\(\bar X\) or \(\hat \mu\) |
| \(\sigma^2\) |
\(S^2\) or \(\hat \sigma\) |
LS0tCnRpdGxlOiAiMi4gQmFzaWMgQ29uY2VwdHMiCmF1dGhvcjogIkxpZXZlbiBDbGVtZW50IgpkYXRlOiAic3RhdE9taWNzLCBHaGVudCBVbml2ZXJzaXR5IChodHRwczovL3N0YXRvbWljcy5naXRodWIuaW8pIgpvdXRwdXQ6CiAgICBodG1sX2RvY3VtZW50OgogICAgICBjb2RlX2Rvd25sb2FkOiB0cnVlCiAgICAgIHRoZW1lOiBjb3NtbwogICAgICB0b2M6IHRydWUKICAgICAgdG9jX2Zsb2F0OiB0cnVlCiAgICAgIGhpZ2hsaWdodDogdGFuZ28KICAgICAgbnVtYmVyX3NlY3Rpb25zOiB0cnVlCi0tLQoKPGEgcmVsPSJsaWNlbnNlIiBocmVmPSJodHRwczovL2NyZWF0aXZlY29tbW9ucy5vcmcvbGljZW5zZXMvYnktbmMtc2EvNC4wIj48aW1nIGFsdD0iQ3JlYXRpdmUgQ29tbW9ucyBMaWNlbnNlIiBzdHlsZT0iYm9yZGVyLXdpZHRoOjAiIHNyYz0iaHR0cHM6Ly9pLmNyZWF0aXZlY29tbW9ucy5vcmcvbC9ieS1uYy1zYS80LjAvODh4MzEucG5nIiAvPjwvYT4KCiMgSW50cm9kdWN0aW9uCmBgYHtyIHNldHVwLCBpbmNsdWRlPUZBTFNFfQprbml0cjo6b3B0c19jaHVuayRzZXQoaW5jbHVkZSA9IFRSVUUsIGNvbW1lbnQgPSBOQSwgZWNobyA9IFRSVUUsCiAgICAgICAgICAgICAgICAgICAgICBtZXNzYWdlID0gRkFMU0UsIHdhcm5pbmcgPSBGQUxTRSkKbGlicmFyeSh0aWR5dmVyc2UpCmxpYnJhcnkoTkhBTkVTKQpgYGAKCmBgYHtyIHBvcDJTYW1wMlBvcCwgb3V0LndpZHRoPSc4MCUnLGZpZy5hc3A9LjgsIGZpZy5hbGlnbj0nY2VudGVyJyxlY2hvPUZBTFNFfQppZiAoInBpIiVpbiVscygpKSBybSgicGkiKQprb3B2b2V0ZXI8LWZ1bmN0aW9uKHgseSxhbmdsZT0wLGw9LjIsY2V4LmRvdD0uNSxwY2g9MTksY29sPSJibGFjayIpCnsKYW5nbGU9YW5nbGUvMTgwKnBpCnBvaW50cyh4LHksY2V4PWNleC5kb3QscGNoPXBjaCxjb2w9Y29sKQpsaW5lcyhjKHgseCtsKmNvcygtcGkvMithbmdsZSkpLGMoeSx5K2wqc2luKC1waS8yK2FuZ2xlKSksY29sPWNvbCkKbGluZXMoYyh4K2wvMipjb3MoLXBpLzIrYW5nbGUpLHgrbC8yKmNvcygtcGkvMithbmdsZSkrbC80KmNvcyhhbmdsZSkpLGMoeStsLzIqc2luKC1waS8yK2FuZ2xlKSx5K2wvMipzaW4oLXBpLzIrYW5nbGUpK2wvNCpzaW4oYW5nbGUpKSxjb2w9Y29sKQpsaW5lcyhjKHgrbC8yKmNvcygtcGkvMithbmdsZSkseCtsLzIqY29zKC1waS8yK2FuZ2xlKStsLzQqY29zKHBpK2FuZ2xlKSksYyh5K2wvMipzaW4oLXBpLzIrYW5nbGUpLHkrbC8yKnNpbigtcGkvMithbmdsZSkrbC80KnNpbihwaSthbmdsZSkpLGNvbD1jb2wpCmxpbmVzKGMoeCtsKmNvcygtcGkvMithbmdsZSkseCtsKmNvcygtcGkvMithbmdsZSkrbC8yKmNvcygtcGkvMitwaS80K2FuZ2xlKSksYyh5K2wqc2luKC1waS8yK2FuZ2xlKSx5K2wqc2luKC1waS8yK2FuZ2xlKStsLzIqc2luKC1waS8yK3BpLzQrYW5nbGUpKSxjb2w9Y29sKQpsaW5lcyhjKHgrbCpjb3MoLXBpLzIrYW5nbGUpLHgrbCpjb3MoLXBpLzIrYW5nbGUpK2wvMipjb3MoLXBpLzItcGkvNCthbmdsZSkpLGMoeStsKnNpbigtcGkvMithbmdsZSkseStsKnNpbigtcGkvMithbmdsZSkrbC8yKnNpbigtcGkvMi1waS80K2FuZ2xlKSksY29sPWNvbCkKfQoKcGFyKG1hcj1jKDAsMCwwLDApLG1haT1jKDAsMCwwLDApKQpwbG90KDAsMCx4bGFiPSIiLHlsYWI9IiIseGxpbT1jKDAsMTApLHlsaW09YygwLDEwKSxjb2w9MCx4YXh0PSJub25lIix5YXh0PSJub25lIixheGVzPUZBTFNFKQpyZWN0KDAsNiwxMCwxMCxib3JkZXI9InJlZCIsbHdkPTIpCnRleHQoLjUsOCwicG9wdWxhdGlvbiIsc3J0PTkwLGNvbD0icmVkIixjZXg9MikKc3ltYm9scyAoMywgOCwgY2lyY2xlcz0xLjUsIGNvbD0icmVkIixhZGQ9VFJVRSxmZz0icmVkIixpbmNoZXM9RkFMU0UsbHdkPTIpCnNldC5zZWVkKDMzMCkKZ3JpZD1zZXEoMCwxLjMsLjAxKQoKZm9yIChpIGluIDE6NTApCnsKCWFuZ2xlMT1ydW5pZihuPTEsbWluPTAsbWF4PTM2MCkKCWFuZ2xlMj1ydW5pZihuPTEsbWluPTAsbWF4PTM2MCkKCXJhZGl1cz1zYW1wbGUoZ3JpZCxwcm9iPWdyaWReMipwaS9zdW0oZ3JpZF4yKnBpKSxzaXplPTEpCglrb3B2b2V0ZXIoMytyYWRpdXMqY29zKGFuZ2xlMS8xODAqcGkpLDgrcmFkaXVzKnNpbihhbmdsZTEvMTgwKnBpKSxhbmdsZT1hbmdsZTIpCn0KdGV4dCg3LjUsOCwiQ2hvbGVzdGVyb2wgaW4gcG9wdWxhdGlvbiIsY29sPSJyZWQiLGNleD0xLjIpCgpyZWN0KDAsMCwxMCw0LGJvcmRlcj0iYmx1ZSIsbHdkPTIpCnRleHQoLjUsMiwic2FtcGxlIixzcnQ9OTAsY29sPSJibHVlIixjZXg9MikKc3ltYm9scyAoMywgMiwgY2lyY2xlcz0xLjUsIGNvbD0icmVkIixhZGQ9VFJVRSxmZz0iYmx1ZSIsaW5jaGVzPUZBTFNFLGx3ZD0yKQpmb3IgKGkgaW4gMDoyKQoJZm9yIChqIGluIDA6NCkKewoKCWtvcHZvZXRlcigyLjEraiooMy45LTIuMSkvNCwxLjEraSkKfQp0ZXh0KDcuNSwyLCJDaG9sZXN0ZXJvbCBpbiBzYW1wbGUiLGNvbD0iYmx1ZSIsY2V4PTEuMikKCmFycm93cygzLDUuOSwzLDQuMSxjb2w9ImJsYWNrIixsd2Q9MykKYXJyb3dzKDcsNC4xLDcsNS45LGNvbD0iYmxhY2siLGx3ZD0zKQp0ZXh0KDEuNSw1LCJFWFAuIERFU0lHTiAoMSkiLGNvbD0iYmxhY2siLGNleD0xLjIpCnRleHQoOC41LDUsIkVTVElNQVRJT04gJlxuSU5GRVJFTkNFICgzKSIsY29sPSJibGFjayIsY2V4PTEuMikKdGV4dCg3LjUsLjUsIkRBVEEgRVhQTE9SQVRJT04gJlxuREVTQ1JJUFRJVkUgU1RBVElTVElDUyAoMikiLGNvbD0iYmxhY2siLGNleD0xLjIpCmBgYAoKCiMjIEV4cGVyaW1lbnRhbCBEZXNpZ24gKDEpCiAgIC0gUmVzZWFyY2hlciBkZXRlcm1pbmVzIHRoZSAqKnBvcHVsYXRpb24qKiB0byB3aGljaCB0aGV5IHdhbnRzIHRvIGdlbmVyYWxpemUgdGhlaXIgY29uY2x1c2lvbnMuCiAgIC0gRmluYW5jaWFsIGFuZCBsb2dpc3RpYyBsaW1pdGF0aW9ucyAkXHJpZ2h0YXJyb3ckICoqcmVwcmVzZW50YXRpdmUgc2FtcGxlKiogZnJvbSBwb3B1bGF0aW9uCiAgIAojIyBEYXRhIGFuYWx5c2lzICgyICYgMykKICAgLSAqKkRhdGEtRXhwbG9yYXRpb24gZW4gRGVzY3JpcHRpdmUgU3RhdGlzdGljcyAoMikqKjogZXhwbG9yZSwgdmlzdWFsaXplLCBzdW1tYXJpemUsIGdhaW4gaW5zaWdodCwgY2hlY2sgYXNzdW1wdGlvbnMKICAgLSAqKlN0YXRpc3RpY2FsIEluZmVyZW5jZSAoMykqKjogR2VuZXJhbGl6ZSB3aGF0IHdlIG9ic2VydmUgaW4gdGhlIHNhbXBsZSB0b3dhcmRzIHRoZSBwb3B1bGF0aW9uIHNvIHRoYXQgd2UgY2FuIGRyYXcgZ2VuZXJhbCBjb25jbHVzaW9ucyBvbiB0aGUgYmlvbG9naWNhbCBwcm9jZXNzIHdlIHN0dWR5LiBXZSBuZWVkIHN0YXRpc3RpY2FsIG1vZGVscyB0byBhbmFseXplIHRoZSBkYXRhLCBhbmQsIHRvIHF1YW50aWZ5IGFuZCByZXBvcnQgb24gdmFyaWFiaWxpdHkgYW5kIHVuY2VydGFpbnR5LiAgCiAgIAotLS0KCiMgRXhhbXBsZQoKLSBOYXRpb25hbCBIZWFsdGggYW5kIE51dHJpdGlvbiBFeGFtaW5hdGlvbiBTdXJ2ZXkgKE5IQU5FUykKLSBBbWVyaWNhbiBkZW1vZ3JhZmljIHN0dWR5Ci0gTGFyZ2UgbnVtYmVyIG9mIHBoeXNpY2FsLCBkZW1vZ3JhcGhpYywgbnV0cml0aW9uYWwsIGxpZmUgc3R5bGUgYW5kIGhlYWx0aCBjaGFyYWN0ZXJpc3RpY3MgCgpgYGB7ciBuaGFuZXMsIHRpZHk9RkFMU0UsZWNobz1GQUxTRX0KbGlicmFyeShOSEFORVMpCmtuaXRyOjprYWJsZSggIE5IQU5FU1tjKDEsNCw1LDYsNyw4KSxjKDEsMywyMCwyMywzNCw3MildCixmb3JtYXQgPSAibWFya2Rvd24iKQpgYGAKCi0tLQoKIyBWYXJpYWJsZXMKCi0gV2UgbWVhc3VyZSAqdmFyaWFibGVzKiBvbiBzdWJqZWN0cyBpbiB0aGUgc2FtcGxlCi0gQSBWYXJpYWJsZSBpcyBhIGNoYXJhY3Rpc3RpYyBlLmcuIERpcmVjdCBjaG9sZXN0ZXJvbCwgQWdlLCBHZW5kZXIsLCAuLi4KLSBJdCB2YXJpZXMgZnJvbSBzdWJqZWN0IHRvdCBzdWJqZWN0IGluIHRoZSBwb3B1bGF0aW9uIGFuZCB0aHVzIGFsc28gd2l0aGluIHRoZSBzYW1wbGUgYXMgd2VsbCBhcyBmcm9tIHNhbXBsZSB0byBzYW1wbGUuCgoKIyMgKlR5cGVzKiBvZiB2YXJpYWJsZXMKCjEuICpRdWFsaXRhdGl2ZSB2YXJpYWJsZXMqOiBhIGxpbWl0ZWQgbnVtYmVyIG9mIG91dGNvbWUgY2F0ZWdvcmllcywgbm9uLW51bWVyaWMuIAoJLSAgKm5vbWluYWwgdmFyaWFibGVzKjogbm8gbmF0dXJhbCBvcmRlbmluZywgZS5nLiBnZW5kZXIsIGJsb29kIGdyb3VwLCBleWUgY29sb3IsIC4uLiAKCS0gICpvcmRpbmFsIHZhcmlhYmxlcyo6IG9yZGVuaW5nLCBlLmcuIEJNSSBjbGFzcywgc21va2luZyBzdGF0dXMgKDE6IG5ldmVyIHNtb2tlZCwgMjogc3RvcHBlZCBzbW9raW5nLCAzOiBzbW9rZXIpCgoyLiAqTnVtZXJpYyB2YXJpYWJsZXMqOgogICAJLSAqZGlzY3JldGUgdmFyaWFibGVzKjogY291bnRzIGUuZy4gbnVtYmVyIG9mIHBhcm5lcnMgaW4gbGlmZSBzcGFuLCAuLi4KCS0gKmNvbnRpbnVvdXMgdmFyaWFibGVzKjogY2FuIChpbiB0aGVvcnkpIHRha2UgZWFjaCBwb3NzaWJsZSB2YWx1ZSBiZXR3ZWVuIGNlcnRhaW4gbGltaXRzIGUuZy4gQWdlLCBXZWlnaHQsIEJNSSwgZmx1b3Jlc2NlbmNlIG1lYXN1cmVtZW50IGluIEVMSVNBIGFzc2F5IAoJCgktIE9mdGVuIGRpY2hvdG9taXNlZCB0byB0dXJuIGl0IGluIGEgbm9taW5hbCBxdWFsaXRhdGl2ZSB2YXJpYWJsZSAkXHJpZ2h0YXJyb3ckIGluZm9ybWF0aW9uIGxvc3MKCi0tLQoKIyBQb3B1bGF0aW9uCgotIEFpbSBvZiBzY2llbnRpZmljIHN0dWR5OiBtYWtlIGdlbmVyYWwgc3RhdGVtZW50cyBvbiBhIHByb2Nlc3MgYXQgdGhlIGxldmVsIG9mIHRoZSBwb3B1bGF0aW9uLiAKLSBFLmcuIGFzc2VzcyBpZiB0aGUgY2hvbGVzdGVyb2wgbGV2ZWwgaXMgb24gYXZlcmFnZSBkaWZmZXJlbnQgYmV0d2VlbiBtYWxlcyBhbmQgZmVtYWxlcyB3aG8gYXJlIGVsZGVyIHRoYW4gMjUuCgokXHJpZ2h0YXJyb3ckIGFzc2VzcyBjaG9sZXN0ZXJvbCBsZXZlbCBpbiBwb3B1bGF0aW9uIGFib3ZlIDI1LgoKLSBQb3B1bGF0aW9uIGluIHN0YXRpc3RpY3MgaXMgYSB0aGVvcmV0aWNhbCBjb25jZXB0CgoJICAtIEl0IGlzIGluIGNvbnRpbnVvdXMgZXZvbHV0aW9uL2NoYW5nZQoJICAtIE9mdGVuIGludGVyZXN0IHRvIGdlbmVyYWxpemUgY29uY2x1c2lvbnMgdG8gZnV0dXJlIHN1YmplY3QgJFxyaWdodGFycm93JCBzbyBwb3B1bGF0aW9uIGNhbm5vdCBiZSBlbnRpcmVseSBvYnNlcnZlZCBhdCB0aGUgcHJlc2VudC4gCiAgCS0gQ2FuIHR5cGljYWxseSBiZSBjb25zaWRlcmVkIHRvIGJlIGluZmluaXRlLiAKCi0gUG9wdWxhdGlvbiBoYXMgdG8gYmUgY2xlYXJseSBkZWZpbmVkISAKCipJbmNsdXNpb24gY3JpdGVyaWEqIGFyZSBjaGFyYWN0ZXJpc3RpY3MgYSBzdWJqZWN0L2V4cGVyaW1lbnRhbCB1bml0IG11c3QgaGF2ZSB0byBiZWxvbmcgdG8gdGhlIHBvcHVsYXRpb24sIGUuZy4KCi0gYWdlIGFib3ZlIDI1Ci0gbm9ybWFsIEJNSQotIC4uLgoKKkV4Y2x1c2lvbiBjcml0ZXJpYSogY2hhcmFjdGVyaXN0aWNzIHRoYXQgdGhlIHN1YmplY3QvZXhwZXJpbWVudGFsIHVuaXQgaXMgbm90IGFsbG93ZWQgdG8gaGF2ZSB0byBiZWxvbmcgdG8gdGhlIHBvcHVsYXRpb24sIGUuZy4gCgotIHByZWduYW5jeSBpbiBzdHVkeSBvbiBuZXcgdHlwZSBvZiBkcnVnCi0gZGlhYmV0ZXMsIGhpc3Rvcnkgb2YgaGFyZCBkcnVncywgbG93IGhlYWx0aCBzdGF0dXMgd2hlbiB0aGUgYWltIGlzIHRvIGRlbGluZWF0ZSBhIHJhbmdlIG9mIG5vcm1hbCB2YWx1ZXMgb2YgYmxvb2QgcHJlc3N1cmUgaW4gYSBwb3B1bGF0aW9uIG9mIGhlYWx0aHkgaW5kaXZpZHVhbHMKLSAuLi4KCi0tLQoKIyBSYW5kb20gVmFyaWFibGVzCgotIFZhcmlhYmxlcyAoZS5nLiBkaXJlY3QgY2hvbGVzdGVyb2wpIHZhcnkgaW4gdGhlIHBvcHVsYXRpb24gZnJvbSBzdWJqZWN0IHRvIHN1YmplY3QhCgotIFZhcmlhYmxlcyBhcmUgdGh1cyAqcmFuZG9tKiBiZWNhdXNlIHRoZWlyIHZhbHVlIGNoYW5nZXMgaW4gdGhlIHBvcHVsYXRpb24uIAoKLSAqKkNydWNpYWwgcXVlc3Rpb24qKjogSG93IHByZWNpc2UgYXJlIHRoZSBjb25jbHVzaW9ucyBvbiB0aGUgcG9wdWxhdGlvbiBiYXNlZCBvbiBhIGdyb3VwIG9mIHN1YmplY3RzIGluIGEgc2FtcGxlISAKCi0gV2Ugd2lsbCB0aHVzIG9ic2VydmUgZGlmZmVyZW5jZXMgZnJvbSBzYW1wbGUgdG8gc2FtcGxlLgoKLSBWYXJpYWJpbGl0eSBvZiB0aGUgZGF0YSBwbGF5cyBhIGNydWNpYWwgcm9sZSEgIAoKLS0tCgojIyBDb252ZW50aW9uCgotIFVzZSBjYXBpdGFsIGxldHRlcnMgZm9yIGEgc3R1ZHkgY2hhcmFjdGVyaXN0aWMgKGUuZy4gZGlyZWN0IGNob2xlc3Rlcm9sKSB0byBpbmRpY2F0ZSB0aGF0IGl0IGNoYW5nZXMgaW4gdGhlIHBvcHVsYXRpb24gd2l0aG91dCB0aGlua2luZyBhYm91dCB0aGUgb2JzZXJ2ZWQgdmFsdWUgb2YgYSBwYXJ0aWN1bGFyIHN1YmplY3QuCgotIFZhcmlhYmxlICRYJCBpcyBhICpyYW5kb20gdmFyaWFibGUqIGFuZCBpcyB0aGUgcmVzdWx0IG9mICpyYW5kb20gc2FtcGxpbmcqIG9mIHRoZSBjaGFyYWN0ZXJpc3RpYyBmcm9tIHRoZSBwb3B1bGF0aW9uLiAKCi0gIFJhbmRvbSB2YXJpYWJsZSAkWCQgaXMgdGh1cyB0aGUgdW5rbm93biB2YXJpYWJsZSB0aGF0IHJlcHJlc2VudCBhIG1lYXN1cmVtZW50IHRoYXQgd2UgcGxhbiB0byBjb2xsZWN0IG9uIGEgcmFuZG9tIHN1YmplY3QsIGJ1dCB0aGF0IHdlIGhhdmUgbm90IGNvbGxlY3RlZCB5ZXQuIAoKLSBUeXBpY2FsbHkgYSBzZXF1ZW5jZSBvZiByYW5kb20gdmFyaWFibGVzICRYXzEsXGxkb3RzIFhfbiQgd2lsbCBiZSBjb2xsZWN0ZWQgaW4gdGhlIHN0dWR5ICh3aXRoIG4gc3ViamVjdHMgb3IgZXhwZXJpbWVudGFsIHVuaXRzKS4gCgotIFRoZSBjb25jZXB0IG9mIHJhbmRvbSB2YXJpYWJsZXMgaXMgbmVjZXNzYXJ5IHRvIHJlYXNvbiBvbiBob3cgdGhlIHJlc3VsdHMgYW5kIGNvbmNsdXNpb25zIGNoYW5nZSBmcm9tIHNhbXBsZSB0byBzYW1wbGUuIAoKLSBSYW5kb20gdmFyaWFibGVzIGNhbiBiZSBxdWFsaXRhdGl2ZSwgcXVhbnRpdGF0aXZlLCBkaXNjcmV0ZSwgY29udGludW91cywgLi4uIAoKLS0tCgojIERlc2NyaWJpbmcgdGhlIHBvcHVsYXRpb24gCgotIEl0IGlzIGltcG9zc2libGUgdG8gcHJlZGljdCB0aGUgdmFsdWUgb2YgYSByYW5kb20gdmFyaWFibGUuCgotIFRoZSByZWFsaXNlZCB2YWx1ZSBvZiAkWCQgaXMgc3ViamVjdCB0byByYW5kb20gdmFyaWFiaWxpdHkuCgotIFN1cHBvc2UgdGhhdCB3ZSBhcmUgaW50ZXJlc3RlZCBpbiB0aGUgSVEgb2Ygc3ViamVjdC4gSWYgd2Uga25vdyBob3cgdGhlIGRhdGEgYXJlIGRpc3RyaWJ1dGVkLCB3ZSBjYW4gdXNlIHByb2JhYmlsaXR5IHRoZW9yeSB0byBjYWxjdWxhdGUgdGhlIHByb2JhYmlsaXR5IHRoYXQgdGhlIElRIG9mIGEgcmFuZG9tIHN1YmplY3Qgb2YgdGhlIHBvcHVsYXRpb24gd2lsbCBiZSBhYm92ZSAxMTAuICAKCi0tLQoKIyMgSW50ZXJtZXp6byBwcm9iYWJpbGl0eSB0aGVvcnkKCiMjIyBEaXNjcmV0ZSByYW5kb20gdmFyaWFibGVzCgotIFN1cG9zZSB0aGF0IHdlIG1lYXN1cmUgYSBkaXNjcmV0ZSByYW5kb20gdmFyaWFibGUgJFgkCgotIEFsbCBwb3NzaWJsZSB2YWx1ZXMgZm9yIHRoZSByYW5kb20gdmFyaWFibGUgJFgkIGFyZSBjYWxsZWQgdGhlIHNhbXBsZSBzcGFjZSAkXE9tZWdhJC4KCiAgICAtIEZvciBnZW5kZXIgdGhlIHNhbXBsZSBzcGFjZSBpcyAkXE9tZWdhPSgwLDEpJCB3aXRoIDAgKG1hbGUpIG9yIDEgKGZlbWFsZSkuIAogICAgLSBTdXBwb3NlIHRoYXQgd2Ugcm9sZSBhIGRpY2UsIHRoZW4gdGhlIHNhbXBsZSBzcGFjZSBpcyAkXE9tZWdhPSgxLDIsMyw0LDUsNikkLiAKCi0gQW4gZXZlbnQgJEEkICBpcyBhIHN1YnNldCBvZiB0aGUgc2FtcGxlIHNwYWNlIAogICAgICAKICAgIC0gR2V0IGFuIGV2ZW4gbnVtYmVyIHdoZW4gcm9sbGluZyBhIGRpY2U6ICRBPSgyLDQsNikkLgogICAgLSBDYW4gYWxzbyBiZSAkQT0oMSkkIG9uZSAgc3Vic2V0IG9mIHRoZSBzYW1wbGUgc3BhY2UuIAoKLSBFdmVudCBzcGFjZSAkXG1hdGhjYWx7QX0kIGlzIHRoZSBjbGFzcyBvZiBhbGwgcG9zc2libGUgZXZlbnRzIGFzc29jaWF0ZWQgd2l0aCBhIGdpdmVuIGV4cGVyaW1lbnQuCgotIFR3byBldmVudHMgKCRBXzEkIGFuZCAkQV8yJCkgYXJlIG11bHRpcGxlIGV4Y2x1c2l2ZSBpZiB0aGV5IGNhbm5vdCBvY2N1ciB0b2dldGhlcgoKICAgIC0gZS5nLiBldmVudCBvZiB0aGUgb2RkIG51bWJlcnMgJEFfMT0oMSwzLDUpJCBhbmQgdGhlIGV2ZW50IG9mIGdldHRpbmcgJEFfMj0oNikkCiAgICAtIHNvICRBXzEgXGJpZ2NhcCBBXzI9XGVtcHR5c2V0JC4KCi0gUHJvYmFiaWxpdHkgJFAoQSkkICBpcyBhIGZ1bmN0aW9uICRQOiBBIFxyaWdodGFycm93IFswLDFdJCB3aGljaCBzYXRpc2ZpZXMKICAgIAogICAgMS4gJFAoQSkgXGdlcSAwJCBhbmQgJFAoQSkgXGxlcSAxJCBmb3IgZWFjaCAkQSBcaW4gXG1hdGhjYWx7QX0kCiAgICAyLiAkUChcT21lZ2EpPTEkCiAgICAzLiBGb3IgbXVsdGlwbGUgZXhjbHVzaXZlIGV2ZW50cyAkQV8xLCBBXzIsIFxsZG90cyBBX2skIHRoZSBwcm9iYWJpbGl0eSAkUChBXzEgXGN1cCBBXzIgXGxkb3RzIFxjdXAgQV9rKT0gUChBXzEpICsgXGxkb3RzICsgUChBX2spJCAKCi0gRGljZSBleGFtcGxlCgogICAgLSBvZGQgbnVtYmVyICRBPSgxLDMsNSkkOiB0aGlzIGlzIHRoZSB1bmlvbiBvZiAzIG11bHRpcGxlIGV4Y2x1c2l2ZSBldmVudHMgJEFfMT0xJCwgJEFfMj01JCBhbmQgJEFfMz01JCBzbwogICAgJFAoQSk9UCgxKStQKDMpK1AoNSk9MS82KzEvNisxLzY9MC41JAogICAgLSAkXE9tZWdhPSgxLDIsMyw0LDUsNikkOiAkUChcT21lZ2EpPTEkCiAgICAKLSBJZiB3ZSBkcmF3IHR3byBzdWJqZWN0cyAoaiBhbmQgaykgaW5kZXBlbmRlbnRseSBmcm9tIHRoZSBwb3B1bGF0aW9uIHRoZW4gdGhlIGpvaW50IHByb2JhYmlsaXR5IG9uICAKJFAoWF9qLFhfayk9IFAoWF9qKVAoWF9qKSQKCi0tLQoKIyMjIyBQcm9iYWJpbGl0eSBtYXNzIGZ1bmN0aW9uIAoKLSBUaGUgcHJvYmFiaWxpdHkgbWFzcyBmdW5jdGlvbiBmb3IgYSByYW5kb20gdmFyaWFibGUgJFgkIGRlc2NyaWJlcyB0aGUgcHJvYmFiaWxpdHkgb2YgZWFjaCBwb3NzaWJsZSB2YWx1ZSBvZiB0aGUgc2FtcGxlIHNwYWNlLgoKLSBFeGFtcGxlOiBHZW5kZXIgaXMgYSBiaW5hcnkgdmFyaWFibGUgKDA6bWFsZSwgMTpmZW1hbGUpIGFuZCBiaW5hcnkgdmFyaWFibGVzIGFyZSBCZXJub3VsbGkgZGlzdHJpYnV0ZWQuIDUwLjglIG9mIHRoZSBzdWJqZWN0cyBvZiB0aGUgQW1lcmljYW4gcG9wdWxhdGlvbiBhcmUgZmVtYWxlIGFuZCA0OS4yJSBhcmUgbWFsZS4gTGV0ICRccGkkIGJlIHRoZSBwcm9iYWJpbGl0eSBvbiBhIGZlbWFsZSAkXHBpPTAuNTA4JC4gCiAgICBzbyAKICAgICQkIFhcc2ltIFxsZWZ0IFx7IAogICAgXGJlZ2lue2FycmF5fXtsY2x9CiAgICBQKFg9MCkgJj0mIDEtXHBpXFwKICAgIFAoWD0xKSAmPSYgXHBpCiAgICBcZW5ke2FycmF5fSBccmlnaHQgLiAkJAogICAgCiAgICBgYGB7cn0KICAgIGRhdGEuZnJhbWUoWD1jKDAsMSkscHJvYj1jKDAuNDkyLDAuNTA4KSkgJT4lCiAgICAgIGdncGxvdChhZXMoeD1YLHhlbmQ9WCx5PTAseWVuZD1wcm9iKSkgKwogICAgICBnZW9tX3NlZ21lbnQoKSArCiAgICAgIHlsYWIoIlByb2JhYmlsaXR5IikKICAgIGBgYAogICAgClJhbmRvbSB2YXJpYWJsZSAkWCQgZm9sbG93cyBhbiBCZXJub3VsbGkgZGlzdHJpYnV0aW9uICRCKFxwaSkkIHdpdGggcGFyYW1ldGVyICRccGk9MC41MDgkLCAKICAgICQkQihccGkpPSBccGleeCgxLVxwaSleeyh4LTEpfSQkCgotLS0KCiMjIyMgQ3VtdWxhdGl2ZSBkaXN0cmlidXRpb24gZnVuY3Rpb24KCi0gVGhlIGN1bXVsYXRpdmUgZGlzdHJpYnV0aW9uIGZ1bmN0aW9uIGlzIHRoZSBmdW5jdGlvbiBGKHgpIHRoYXQgY2FsY3VsYXRlcyB0aGUgcHJvYmFiaWxpdHkgdG8gb2JzZXJ2ZSBhIHJhbmRvbSB2YXJpYWJsZSBYIGZvciB3aGljaCAkWFxsZXEgeCQ6IAokJCBGKHgpID0gXHN1bVxsaW1pdHNfe1xmb3JhbGwgWFxsZXEgeH0gUCh4KSQkCgotIEdlbmRlciBleGFtcGxlICRGKDApPTEtXHBpJCBhbmQgRigxKT1QKFg9MCkgKyBQKFg9MSk9MQoKICAgIGBgYHtyfQogICAgZGF0YS5mcmFtZShYPWMoMCwxKSxjdW1wcm9iPWMoMC40OTIsMSkpICU+JQogICAgICBnZ3Bsb3QoYWVzKHg9WCx4ZW5kPVgseT0wLHllbmQ9Y3VtcHJvYikpICsKICAgICAgZ2VvbV9zZWdtZW50KCkgKwogICAgICB5bGFiKCJGKHgpIikKICAgIGBgYAoKLSBEaWNlOiAKCiAgICBgYGB7cn0KICAgIGRhdGEuZnJhbWUoWD0xOjYsY3VtcHJvYj1jdW1zdW0ocmVwKDEvNiw2KSkpICU+JQogICAgICBnZ3Bsb3QoYWVzKHg9WCx4ZW5kPVgseT1yZXAoMCw2KSx5ZW5kPWN1bXByb2IpKSArCiAgICAgIGdlb21fc2VnbWVudCgpICsKICAgICAgeWxhYigiRih4KSIpCiAgICBgYGAKCi0tLQoKIyMjIyBNZWFuCgpUaGUgbWVhbiBvciB0aGUgZXhwZWN0ZWQgdmFsdWUgJEVbWF0kIG9mIGEgZGlzY3JldGUgcmFuZG9tIHZhcmlhYmxlIGlzIGdpdmVuIGJ5CgokJEVbWF09XHN1bVxsaW1pdHNfe3hcaW5cT21lZ2F9IHggUChYPXgpJCQKCi0gR2VuZGVyIGV4YW1wbGUKICAgIAogICAgLSAkRVtYXT0gMCBcdGltZXMgKDEtXHBpKSArIDEgXHRpbWVzIFxwaSA9IFxwaSQKICAgIC0gVGhlIG1lYW4gZXF1YWxzICRFW1hdPTAuNTA4JC4KCi0gRGljZSBleGFtcGxlOiAKCiQkCkVbWF09IDEgXHRpbWVzIDEvNiArIDIgXHRpbWVzIDEvNiArIFxsZG90cyArIDYgXHRpbWVzIDEvNiA9IGByIHN1bSgxOjYpLzZgCiQkCgotLS0KCiMjIyMgVmFyaWFuY2UKClRoZSB2YXJpYW5jZSBpcyBhIG1lYXN1cmUgZm9yIHRoZSB2YXJpYWJpbGl0eSBvZiBhIHJhbmRvbSB2YXJpYWJsZSBhbmQgIGlzIGdpdmVuIGJ5CgokJEVbKFgtRVtYXSleMl09XHN1bVxsaW1pdHNfe3hcaW5cT21lZ2F9ICh4LUVbWF0pXjIgUChYPXgpJCQKCi0gR2VuZGVyIGV4YW1wbGUKICAgIFxiZWdpbntlcW5hcnJheX0KICAgIEVbKFgtRVtYXSleMl0mPSYoMC1ccGkpXjJcdGltZXMgKDEtXHBpKSsoMS1ccGkpXjIgXHRpbWVzIFxwaVxcCiAgICAmPSYgXHBpXjIgKDEtXHBpKSArICgxLVxwaSleMiBccGlcXAogICAgJj0mXHBpICgxLVxwaSkoXHBpKzEtXHBpKVxcCiAgICAmPSZccGkoMS1ccGkpCiAgICBcZW5ke2VxbmFycmF5fQoKLS0tCgojIyMgQ29udGludW91cyByYW5kb20gdmFyaWFibGUgCgoKLSBUaGUgZGVuc2l0eSBmdW5jdGlvbiAkZih4KSQgZGVzY3JpYmVzIGhvdyBsaWtlbHkgaXQgaXMgdG8gb2JzZXJ2ZSBhIHBhcnRpY3VsYXIgdmFsdWUgb2YgcmFuZG9tIHZhcmlhYmxlIFggd2hlbiB3ZSBzYW1wbGUgYSByYW5kb20gc3ViamVjdCBmcm9tIHRoZSBwb3B1bGF0aW9uLiAKCi0gTWFueSBiaW9sb2dpY2FsIGNoYXJhY3RlcmlzdGljcyBhcmUgYXBwcm94aW1hdGl2ZWx5IG5vcm1hbGx5IGRpc3RyaWJ1dGVkICh1cG9uIHRyYW5zZm9ybWF0aW9uKSAKICAgICQkZih4KSA9IFxmcmFjezF9e1xzcXJ0ezJccGlcc2lnbWFeMn19IGVeey1cZnJhY3soeC1cbXUpXjJ9ezJcc2lnbWFeMn19JCQKCi0gVGhpcyBpcyBkZW5vdGVkIGluIHNob3J0aGFuZCBhcyAkZih4KSA9IE4oXG11LFxzaWdtYV4yKSQKCi0gVGhlIElRIGluIHRoZSBwb3B1bGF0aW9uIGlzIGtub3duIHRvIGZvbGxvdyBhIG5vcm1hbCBkaXN0cmlidXRpb24gd2l0aCBtZWFuICRcbXU9MTAwJCBhbmQgc3RhbmRhcmQgZGV2aWF0aW9uICRcc2lnbWE9MTUkLiAgCiQkSVEgXHNpbSBOKDEwMCwxNV4yKSQkCiAgICAKCi0gUiB3ZSBjYW4gdXNlIHRoZSBkbm9ybSBmdW5jdGlvbiB0byBjYWxjdWxhdGUgdGhlIGRlbnNpdHkgb2YgcGFydGljdWxhciB2YWx1ZXMgb2YgWD14LgoKLSBUaGUgYXJndW1lbnRzIG9mIGBkbm9ybWAgYXJlIGBtZWFuYCAoJFxtdSQpIGFuZCBgc2RgIChzdGFuZGFyZCBkZXZpYXRpb24gJFxzaWdtYSQpLiAKCmBgYHtyIElRLCBmaWcuYWxpZ249J2NlbnRlcid9CnBhcihtYXI9Yyg1LCA0LCA0LCAyKSArIDAuMSwgbWFpPWMoMS4wMiwwLjgyLDAuODIsMC40MikpCmdyaWQgPC0gc2VxKDQwLDE2MCwuMSkKcGxvdChncmlkLGRub3JtKGdyaWQsbWVhbj0xMDAsc2Q9MTUpLAogICAgIHhsYWI9IklRIiwKICAgICBjb2w9Mix5bGFiPSJEZW5zaXRlaXQiLHR5cGU9ImwiLGx3ZD0yLGNleC5sYWI9MS41LGNleC5heGlzPTEuNSkKYGBgCgotIFdpdGhpbiBjZXJ0YWluIGxpbWl0cywgY29udGludW91cyB2YXJpYWJsZXMgY2FuIHRha2UgYWxsIHBvc3NpYmxlIHZhbHVlcyBzbyB0aGUgc2FtcGxlIHNwYWNlICRcT21lZ2EkIGlzIGluZmluaXRlbHkgbGFyZ2UuIAoKLS0tCgojIyMjIEN1bXVsYXRpdmUgZGlzdHJpYnV0aW9uCgotIEFnYWluIHRoZSBjdW11bGF0aXZlIGRpc3RyaWJ1dGlvbiAkRihYKT1QKFhcbGVxIHgpJC4KCi0gQmVjYXVzZSBYIGlzIGNvbnRpbnVvdXMgd2Ugd2lsbCBjYWxjdWxhdGUgdGhpcyBwcm9iYWJpbGl0eSB1c2luZyBhbiBpbnRlZ3JhbAokJEYoeCk9XGludCBcbGltaXRzX3stXGluZnR5fV54IGYoeCkgZHgkJAoKLSBOb3RlIHRoYXQgJGYoeCk9MCQgaWYgeCBkb2VzIG5vdCBiZWxvbmcgdG8gdGhlIHNhbXBsZSBzcGFjZS4gCgotIFdlIGNhbiBjYWxjdWxhdGUgJEYoeCkkIGZvciBhIG5vcm1hbGx5IGRpc3RyaWJ1dGVkIHJhbmRvbSB2YXJpYWJsZSB1c2luZyB0aGUgYHBub3JtYCBmdW5jdGlvbiBhZ2FpbiB3aXRoIGFyZ3VtZW50cyBgbWVhbmAgYW5kIGBzZGAuIAoKYGBge3J9CnBsb3QoZ3JpZCxwbm9ybShncmlkLG1lYW49MTAwLHNkPTE1KSx0eXBlPSJsIix4bGFiPSJJUSIseWxhYj0iUHJvYmFiaWxpdHkiKQpgYGAKClNvIHRoZSBwcm9iYWJpbGl0eSB0aGF0IHRoZSBJUSBvZiBhIHJhbmRvbSBzdWJqZWN0IGlzIGJlbG93IDgwIGNhbiBiZSBvYnRhaW5lZCBieQoKYGBge3J9CnBub3JtKDgwLG1lYW49MTAwLHNkPTE1KQpgYGAKCmBgYHtyIGZpZy5hbGlnbj0nY2VudGVyJyxlY2hvPUZBTFNFfQpncmlkMjwtc2VxKDQwLDgwLC4wMSkKcGxvdChncmlkLGRub3JtKGdyaWQsbWVhbj0xMDAsc2Q9MTUpLAogICAgIHhsYWI9IklRIiwKICAgICBjb2w9Mix5bGFiPSJEZW5zaXRlaXQiLHR5cGU9ImwiLGx3ZD0yLGNleC5sYWI9MS41LGNleC5heGlzPTEuNSkKcG9seWdvbih4PWMoZ3JpZDIsODAsNDApLHk9Yyhkbm9ybShncmlkMiwxMDAsMTUpLDAsMCksY29sPTIsYm9yZGVyPTIpCnRleHQoODAsZG5vcm0oODAsbWVhbj0xMDAsc2Q9MTUpLHBhc3RlMCgiUChYIDwgODApID0gIixyb3VuZChwbm9ybSg4MCwxMDAsMTUpKjEwMCwxKSwiJSIpLGNvbD0yLGNleD0xLjUscG9zPTQpCmBgYAoKYGBge3IgZmlnLmFsaWduPSdjZW50ZXInLGVjaG89RkFMU0V9CnBsb3QoZ3JpZCxwbm9ybShncmlkLG1lYW49MTAwLHNkPTE1KSx0eXBlPSJsIix4bGFiPSJJUSIseWxhYj0iUHJvYmFiaWxpdHkiLGx3ZD0yLGNvbD0yKQpsaW5lcyhjKDgwLDgwLDgwLDApLGMoMCxyZXAocG5vcm0oODAsMTAwLDE1KSwzKSksbHR5PTIpCmBgYAoKLSBGb3IgdGhlIGxhcmdlc3QgcG9zc2libGUgdmFsdWUgb2YgJFgkIHdlIGludGVncmF0ZSBvdmVyIHRoZSBlbnRpcmUgc2FtcGxlIHNwYWNlICRcT21lZ2EkIHNvIAokJFxpbnQgXGxpbWl0c197eCBcaW4gXE9tZWdhfSBmKHgpIGR4PTEkJAoKLSBTbyB0aGUgYXJlYSB1bmRlciB0aGUgZGVuc2l0eSBmdW5jdGlvbiBlcXVhbHMgMSEgCgotLS0KCiMjIyMgTWVhbiBhbmQgVmFyaWFuY2UuIAoKLSBUaGUgbWVhbiBvciB0aGUgZXhwZWN0ZWQgdmFsdWUgJEVbWF0kIG9mIGEgY29udGludW91cyByYW5kb20gdmFyaWFibGUgaXMgZ2l2ZW4gYnkgCgokJFxpbnQgXGxpbWl0c197eCBcaW4gXE9tZWdhfSB4IGYoeCkgZHgkJCAKCi0gRm9yIHRoZSBub3JtYWwgZGlzdHJpYnV0aW9uIAokJFxpbnQgXGxpbWl0c197LVxpbmZ0eX1eeytcaW5mdHl9IHggZih4KSBkeCA9IFxtdSQkCgotIFRoZSB2YXJpYW5jZSAkRVsoWC1FW1hdKV4yXSQgaXMgZ2l2ZW4gYnkgCgokJFxpbnQgXGxpbWl0c197eCBcaW4gXE9tZWdhfSAoeC1FW1hdKV4yIGYoeCkgZHgkJCAKCi0gRm9yIHRoZSBub3JtYWwgZGlzdHJpYnV0aW9uIHdlIGdldCAKCiQkXGludCBcbGltaXRzX3stXGluZnR5fV57K1xpbmZ0eX0gKHgtXG11KV4yIGYoeCkgZHggPSBcc2lnbWFeMiQkCgotIEl0IGlzIG9mdGVuIGRpZmZpY3VsdCB0byBpbnRlcnByZXQgdGhlIHZhcmlhbmNlIGJlY2F1c2UgaXQgaXMgbm90IGluIHRoZSBzYW1lIHVuaXQgYXMgdGhlIHJhbmRvbSB2YXJpYWJsZSBhbmQgdGhlIG1lYW4uIApXZSB0aGVyZWZvcmUgb2Z0ZW4gdXNlIHRoZSBzdGFuZGFyZCBkZXZpYXRpb24KCiQkU0Q9XHNxcnR7RVsoWC1FW1hdKV4yXX0kJAoKClRoZSBTRCBmb3IgYSBub3JtYWwgZGlzdHJpYnV0aW9uLCAkXHNpZ21hJCBoYXMgdGhlIG5pY2UgaW50ZXJwcmV0YXRpb24gdGhhdCBhcHByb3hpbWF0ZWx5IDY4JSBvZiB0aGUgcG9wdWxhdGlvbiBoYXMgYSB2YWx1ZSBmb3IgdGhlIGNoYXJhY3RlcmlzdGljIFggd2l0aGluIHRoZSBpbnRlcnZhbCBvZiBvbmUgc3RhbmRhcmQgZGV2aWF0aW9uICgkXHNpZ21hJCkgYXJvdW5kIHRoZSBtZWFuOiAKCiQkUChcbXUtXHNpZ21hIDwgWCA8IFxtdSArIFxzaWdtYSkgXGFwcHJveCAwLjY4JCQKCgpgYGB7ciBmaWcuYWxpZ249J2NlbnRlcicsZWNobz1GQUxTRX0KZ3JpZDI8LXNlcSg4NSwxMTUsLjAxKQpwbG90KGdyaWQsZG5vcm0oZ3JpZCxtZWFuPTEwMCxzZD0xNSksCiAgICAgeGxhYj0iSVEiLAogICAgIGNvbD0yLHlsYWI9IkRlbnNpdGVpdCIsdHlwZT0ibCIsbHdkPTIsY2V4LmxhYj0xLjUsY2V4LmF4aXM9MS41KQpwb2x5Z29uKHg9YyhncmlkMiwxMTUsODUpLHk9Yyhkbm9ybShncmlkMiwxMDAsMTUpLDAsMCksY29sPSJncmV5Iixib3JkZXI9ImdyZXkiKQp0ZXh0KDExNSxkbm9ybSgxMTUsbWVhbj0xMDAsc2Q9MTUpLHBhc3RlMCgiUCg4NTxYPDExNSkgPSAiLHJvdW5kKChwbm9ybSgxMTUsMTAwLDE1KS1wbm9ybSg4NSwxMDAsMTUpKSoxMDAsMSksIiUiKSxjb2w9MixjZXg9MS4zLHBvcz00KQphYmxpbmUodj0xMDApCnRleHQoNCwwLGV4cHJlc3Npb24obXUpKQpsaW5lcyhjKDg1LDExNSkscmVwKGRub3JtKDExNSwxMDAsMTUpLDIpKQp0ZXh0KDEwNy41LGRub3JtKDExNC41LDEwMCwxNSksZXhwcmVzc2lvbihzaWdtYSkpCnRleHQoMTAwLTE1LzIsZG5vcm0oMTE0LjUsMTAwLDE1KSxleHByZXNzaW9uKHNpZ21hKSkKYGBgCgotIEZvciBub3JtYWxseSBkaXN0cmlidXRlZCByYW5kb20gdmFyaWFibGVzIGFwcHJveGltYXRlbHkgOTUlIG9mIHRoZSBzdWJqZWN0cyBpbiB0aGUgcG9wdWxhdGlvbiBoYXZlIGEgdmFsdWUgdGhhdCBsYXlzIGluIHR3byBzdGFuZGFyZCBkZXZpYXRpb25zICgkMiBcc2lnbWEkKSBvZiB0aGUgbWVhbgoKJCRQW1xtdSAtIDIgXHNpZ21hIDwgWCA8IFxtdSArIDIgXHNpZ21hXVxhcHByb3ggMC45NSQkCmBgYHtyIGZpZy5hbGlnbj0nY2VudGVyJyxlY2hvPUZBTFNFfQpncmlkMjwtc2VxKDcwLDEzMCwuMDEpCnBsb3QoZ3JpZCxkbm9ybShncmlkLG1lYW49MTAwLHNkPTE1KSwKICAgICB4bGFiPSJJUSIsCiAgICAgY29sPTIseWxhYj0iRGVuc2l0ZWl0Iix0eXBlPSJsIixsd2Q9MixjZXgubGFiPTEuNSxjZXguYXhpcz0xLjUpCnBvbHlnb24oeD1jKGdyaWQyLDEzMCw3MCkseT1jKGRub3JtKGdyaWQyLDEwMCwxNSksMCwwKSxjb2w9ImdyZXkiLGJvcmRlcj0iZ3JleSIpCnRleHQoMTE1LGRub3JtKDExNSxtZWFuPTEwMCxzZD0xNSkscGFzdGUwKCJQKDg1PFg8MTE1KSA9ICIscm91bmQoKHBub3JtKDEzMCwxMDAsMTUpLXBub3JtKDcwLDEwMCwxNSkpKjEwMCwxKSwiJSIpLGNvbD0yLGNleD0xLjMscG9zPTQpCmFibGluZSh2PTEwMCkKdGV4dCg0LDAsZXhwcmVzc2lvbihtdSkpCmxpbmVzKGMoNzAsMTMwKSxyZXAoZG5vcm0oMTMwLDEwMCwxNSksMikpCnRleHQoMTE1LGRub3JtKDEyOCwxMDAsMTUpLGV4cHJlc3Npb24oc2lnbWEpKQp0ZXh0KDg1LGRub3JtKDEyOCwxMDAsMTUpLGV4cHJlc3Npb24oc2lnbWEpKQpgYGAKCi0tLQoKLSBJbiBSIGN1bXVsYXRpdmUgZGlzdHJpYnV0aW9uIGNhbiBiZSBjYWxjdWxhdGVkIHdpdGggdGhlIGZ1bmN0aW9uIHJub3JtLiBUaGlzIGZ1bmN0aW9uIGhhcyBhcmd1bWVudHMgcSB0aGUgcXVhbnRpbGUsIHRoZSBtZWFuIGFuZCB0aGUgc3RhbmRhcmQgZGV2aWF0aW9uLgoKLSBJZiB5b3Ugd2FudCBoZWxwIHlvdSBjYW4gYWx3YXlzIHR5cGU6CgpgYGB7cn0KP3Bub3JtCmBgYAoKLSBXaGF0IGlzIHRoZSBwcm9iYWJpbGl0eSB0aGF0IGEgcmFuZG9tIHN1YmplY3QgaW4gdGhlIHBvcHVsYXRpb24gd2lsbCBoYXZlIGFuIElRIGJlbG93IDkwPwoKYGBge3J9CnBub3JtKHE9OTAsbWVhbj0xMDAsc2Q9MTUpCmBgYAoKLSBXaGF0IGlzIHRoZSBwcm9iYWJpbGl0eSB0aGF0IGEgcmFuZG9tIHN1YmplY3QgaW4gdGhlIHBvcHVsYXRpb24gd2lsbCBoYXZlIGFuIElRIGJlbG93IDExMD8KCi0gV2hhdCBpcyB0aGUgcHJvYmFiaWxpdHkgdGhhdCBhIHJhbmRvbSBzdWJqZWN0IGluIHRoZSBwb3B1bGF0aW9uIHdpbGwgaGF2ZSBhbiBJUSBiZXR3ZWVuIDkwIGFuZCAxMTA/CgotLS0KCiMjIFN0YW5kYXJkaXphdGlvbgoKLSBOb3JtYWwgZGF0YSBhcmUgb2Z0ZW4gc3RhbmRhcmRpemVkLiAKCiQkej1cZnJhY3t4LVxtdX17XHNpZ21hfSQkCgotIFVwb24gc3RhbmRhcmRpemF0aW9uIHRoZSBkYXRhIGZvbGxvdyBhIHN0YW5kYXJkIG5vcm1hbCBkaXN0cmlidXRpb24gd2l0aCBtZWFuICRcbXU9MCQgYW5kIHZhcmlhbmNlICRcc2lnbWFeMj0xJDoKJCR6IFxzaW0gTigwLDEpJCQKCldlIGNhbiB1c2UgdGhlIHFub3JtIGZ1bmN0aW9uIHRvIGNhbGN1bGF0ZSB0aGUgcXVhbnRpbGUgJHpfezIuNVwlfSQgYW5kICR6X3s5Ny41XCV9JCBjb3JyZXNwb25kaW5nIHRvICRGKHpfezIuNVwlfSk9MC4wMjUkIGFuZCAkRih6X3s5Ny41XCV9KT0wLjk3NSQsIHJlc3BlY3RpdmVseS4gCgpgYGB7cn0KcW5vcm0oMC4wMjUpCnFub3JtKDAuOTc1KQoKYGBgCgpUaGlzIGluZGVlZCAgaW5kaWNhdGVzIHRoYXQgYWJvdXQgOTcuNSUtMi41JT05NSUgb2YgYSBzdGFuZGFyZCBub3JtYWwgcmFuZG9tIHZhcmlhYmxlIGZhbGxzIHdpdGhpbiB0aGUgaW50ZXJ2YWwgWy0yLDJdLCBvciB3aXRoaW4gMiB0aW1lcyB0aGUgc3RhbmRhcmQgZGV2aWF0aW9uICgkXHNpZ21hPTEkKSBmcm9tIHRoZSBtZWFuICgkXG11PTAkKS4KCi0tLQoKIyBTYW1wbGUKCi0gSW4gcmVhbCBzdHVkaWVzIHdlIHR5cGljYWxseSBkbyBub3Qga25vdyB0aGUgZGlzdHJpYnV0aW9uIGluIHRoZSBwb3B1bGF0aW9uLgoKLSBEdWUgdG8gZmluYW5jaWFsIGFuZCBsb2dpc3RpYyByZWFzb25zIHdlIGNhbiBhbG1vc3QgbmV2ZXIgc3R1ZHkgdGhlIGVudGlyZSBwb3B1bGF0aW9uLgoKLSBUaGUgcG9wdWxhdGlvbiBwYXJhbWV0ZXJzIChlLmcuIG1lYW4gSVEsIHZhcmlhbmNlIG9mIElRKSAgY2FuIHRoZXJlZm9yZSBub3QgYmUgb2J0YWluZWQgd2l0aG91dCBlcnJvci4KCi0gT25seSBhcyBzbWFsbCBzdWJzZXQgb2YgdGhlIHBvcHVsYXRpb24gY2FuIGJlIHN0dWRpZWQ6IHRoZSAqc2FtcGxlKiAKLSBTYW1wbGUgYWNjb3JkaW5nIHRvIGEgc3RydWN0dXJlZCBkZXNpZ246IHNlbGVjdCAqKnN1YmplY3QgY29tcGxldGVseSBhdCByYW5kb20gZnJvbSB0aGUgcG9wdWxhdGlvbioqIHNvIHRoYXQgZXZlcnkgc3ViamVjdCBoYXMgYW4gZXF1YWwgcHJvYmFiaWxpdHkgdG8gZW5kIHVwIGluIHRoZSBzYW1wbGUgJFxyaWdodGFycm93JCAqKlJlcHJlc2VudGF0aXZlIHNhbXBsZSoqLgoKLSBUaGUgc2FtcGxlICR4XzEsIHhfMiwgLiAuIC4gLCB4X3tufSQgY2FuIGJlIGNvbnNpZGVyZWQgdG8gYmUgJG4kIHJlYWxpc2F0aW9ucyBvZiB0aGUgc2FtZSByYW5kb20gdmFyaWFibGUgJFgkLCBmb3Igc3ViamVjdHMgJGkgPSAxLDIsLi4uLG4kLgoKLSBUaGUgZGlzdHJpYnV0aW9uIGluIHRoZSBwb3B1bGF0aW9uIGlzIHVua25vd24gYW5kIGhhcyB0byBiZSBlc3RpbWF0ZWQuIAoKLSBJZiB3ZSBjYW4gYXNzdW1lIHRoYXQgdGhlIHN0dWRpZWQgY2hhcmFjdGVyaXN0aWMgZm9sbG93cyBhIHBhcnRpY3VsYXIgZGlzdHJpYnV0aW9uIChlLmcuIGEgbm9ybWFsIGRpc3RyaWJ1dGlvbiAkTihcbXUsXHNpZ21hXjIpJCB0aGVuIHdlIG9ubHkgaGF2ZSB0byBlc3RpbWF0ZSB0aGUgcG9wdWxhdGlvbiBwYXJhbWV0ZXJzIChlLmcgJFxtdSQgYW5kICRcc2lnbWFeMiQpIGJhc2VkIG9uIHRoZSBzYW1wbGUuIAoKLSBXZSByZWZlciB0byB0aGVtIGFzIGVzdGltYXRlcyBhbmQgZGVub3RlIHRoZW0gYnkgJFxoYXQgXG11JCBhbmQgJFxoYXQgXHNpZ21hXjIkLgoKLS0tCgojIyBOSEFORVMgZXhhbXBsZQoKLSBHZW5kZXIgaW4gdGhlIHBvcHVsYXRpb24KLSBTZWxlY3QgJG49MTAwMDAkIHN1YmplY3RzIGF0IHJhbmRvbSBmcm9tIHRoZSBBbWVyaWNhbiBwb3B1bGF0aW9uLgotIE9uY2UgdGhlIHJhbmRvbSBpbmRpdmlkdWFscyBhcmUgc2FtcGxlZCBmcm9tIHRoZSBwb3B1bGF0aW9uIHdlIGhhdmUgb2JzZXJ2ZWQgJG4kIHJlYWxpc2F0aW9ucyBvZiB0aGUgcmFuZG9tIHZhcmlhYmxlICRYJC4gCgotICpDb252ZW50aW9uKjogT2JzZXJ2ZWQgdmFsdWVzICRccmlnaHRhcnJvdyQgYXJlIGRlbm90ZWQgd2l0aCBhIHNtYWxsIGxldHRlciAkeCQuCgotICR4JCBpcyBhIHBhcnRpY3VsYXIgdmFsdWUgbWVhc3VyZWQvb2JzZXJ2ZWQgaW4gYSBjb25kdWN0ZWQgZXhwZXJpbWVudCBhbmQgbm8gbG9uZ2VyIGFuIHVua25vd24gdmFyaWFibGUuCgojIyBJbiBzdW1tYXJ5ICAKCiAgLSBVbmtub3duIHZhbHVlcyBvZiB0aGUgc3R1ZGllZCBwb3B1bGF0aW9uIGNoYXJhY3RlcmlzdGljIGZvciAxIHRvICRuJCBzdWJqZWN0cyBpbiBhIHNhbXBsZSBhcmUgcmFuZG9tIHZhcmlhYmxlczogJFhfMSwgXGxkb3RzLCBYX24kIAogIC0gV2UgaGF2ZSB0byByZWFzb24gb24gdGhpcyBpbiBvcmRlciB0byB1bmRlcnN0YW5kIGhvdyB0aGUgb2JzZXJ2YXRpb25zLCBlc3RpbWF0ZXMgYW5kIGNvbmNsdXNpb25zIG9mIGEgc3R1ZHkgY2FuIGNoYW5nZSBmcm9tIHNhbXBsZSB0byBzYW1wbGUuIAogIC0gSW4gYSBzYW1wbGUgd2Ugb2JzZXJ2ZSB0aGUgcmVhbGlzZWQgb3V0Y29tZXMgJHhfMSwgeF8yLCBcZG90cywgeF9uJDogZS5nLiB0aGUgb2JzZXJ2ZWQgZ2VuZGVycyBvciB0aGUgb2JzZXJ2ZWQgZGlyZWN0IGNob2xlc3Rlcm9sIGxldmVscyBvZiB0aGUgc3ViamVjdHMgaW4gdGhlIHNhbXBsZS4gCgotLS0KCiMgR2VuZGVyIEV4YW1wbGUKCmBgYHtyfQpsaWJyYXJ5KE5IQU5FUykKTkhBTkVTICU+JSBnZ3Bsb3QoYWVzKHg9R2VuZGVyKSkgKyBnZW9tX2JhcigpCmBgYAoKLSBHZW5kZXIgaXMgYSBiaW5hcnkgdmFyaWFibGUuIAotIEl0IHRodXMgZm9sbG93cyBhIEJlcm5vdWxsaSBkaXN0aWJ1dGlvbi4gCi0gVGhlIHBhcmFtZXRlciBvZiBhIEJlcm5vdWxsaSBkaXN0cmlidXRpb24gaXMgdGhlIG1lYW4gJFxwaSQuIAotIFdlIGNhbiBlc3RpbWF0ZSAkXHBpJCBiYXNlZCBvbiB0aGUgc2FtcGxlIHVzaW5nIHRoZSBzYW1wbGUgbWVhbiAkXGJhciB4ID0gXHN1bVxsaW1pdHNfe2k9MX1ebiB4X2kkIAotIE5vdGUsIHRoYXQgdGhlIHNhbXBsZSBtZWFuIGlzIGFsc28gYSByYW5kb20gdmFyaWFibGUhIEl0IGFsc28gdmFyaWVzIGZyb20gc2FtcGxlIHRvIHNhbXBsZSEKCmBgYHtyfQpOSEFORVMkR2VuZGVyICU+JSBoZWFkCmBgYAoKLSBOb3RlLCB0aGF0IEdlbmRlciBpcyBhIGZhY3RvciBhbmQgdGhhdCB0aGUgZmVtYWxlcyBhcmUgdGhlIHJlZmVyZW5jZSBjbGFzcyAoZmlyc3QgY2xhc3MpLiAKLSBSIGJ5IGRlZmF1bHQgdXNlcyB0aGUgbGV2ZWwgd2hpY2ggY29tZXMgZmlyc3QgaW4gdGhlIGFsZmFiZXQgYXMgdGhlIHJlZmVyZW5jZSBjbGFzcy4gCi0gV2UgY2FuIHJlY29kZSB0aGUgR2VuZGVyIHVzaW5nIGEgMCBhbmQgMSBjb2RpbmcuIAotIFdoZW4gd2UgdXNlIHRoZSBhcy5udW1lcmljKCkgZnVuY3Rpb24gdGhlIGZhY3RvciBHZW5kZXIgaXMgdHJhbnNmb3JtZWQgaW4gYSBudW1lcmljIHZhbHVlLiBJdCBoYXMgdHdvIHZhbHVlcyAxIG9yIDIuIDEgc3RhbmRzIGZvciB0aGUgZmlyc3QgbGV2ZWwgKGZlbWFsZXMpIGFuZCAyIGZvciB0aGUgc2Vjb25kIGxldmVsIG1hbGVzLiBJZiB3ZSBzdWJ0cmFjdCAxIGZyb20gaXQgd2UgaGF2ZSBhIDAgYW5kIDEgZW5jb2RpbmcgKDAgZm9yIGZlbWFsZXMgYW5kIDEgZm9yIG1hbGVzKS4KCmBgYHtyfQpOSEFORVM8LU5IQU5FUyAlPiUgbXV0YXRlKGdlbmRlcj1hcy5udW1lcmljKEdlbmRlciktMSkKbWVhbihOSEFORVMkZ2VuZGVyKQpgYGAKCi0gTm90ZSwgdGhhdCBkdWUgdG8gdGhlIGVuY29kaW5nIHRoZSBzYW1wbGUgbWVhbiBpcyBhbiBlc3RpbWF0ZSBmb3IgdGhlIGZyYWN0aW9uIG9mIG1hbGVzIGluIHRoZSBwb3B1bGF0aW9uLiAKCi0gQWx3YXlzIGJlIGNhcmVmdWwgd2l0aCB0aGUgZW5jb2RpbmchCgotLS0KCiMgRGlyZWN0IGNob2xlc3Rlcm9sIGV4YW1wbGUKCiMjIEVtcGlyaWNhbCBkaXN0cmlidXRpb24KCi0gV2UgY2FuIGVzdGltYXRlIHRoZSBkaXJlY3QgY2hvbGVzdGVyb2wgZGlzdHJpYnV0aW9uIG9mIGZlbWFsZXMgdXNpbmcgYSBoaXN0b2dyYW0gCgpgYGB7cn0KTkhBTkVTICU+JSBmaWx0ZXIoR2VuZGVyPT0iZmVtYWxlIikgJT4lIApnZ3Bsb3QoYWVzKHg9RGlyZWN0Q2hvbCkpICsgCmdlb21faGlzdG9ncmFtKCkKYGBgCgotIE5vdGUsIHRoYXQgdGhlIGRpc3RyaWJ1dGlvbiBpcyBza2V3ZWQgd2l0aCBhIHRhaWwgdG8gdGhlIHJpZ2h0LiAKCi0gV2UgY2FuIGVzdGltYXRlIHRoZSBjdW11bGF0aXZlIGRpc3RyaWJ1dGlvbiBmdW5jdGlvbiB1c2luZyB0aGUgZW1waXJpY2FsIGN1bXVsYXRpdmUgZGlzdHJpYnV0aW9uIGZ1bmN0aW9uLiAKICAgIC0gRXZlcnkgb2JzZXJ2YXRpb24gaW4gdGhlIHNhbXBsZSBpcyBvYnNlcnZlZCBvbmNlLgogICAgLSBTbyB0aGUgZW1waXJpY2FsIGRpc3RyaWJ1dGlvbiBvZiB0aGUgc2FtcGxlIGlzIGEgZGlzY3JldGUgZGlzdHJpYnV0aW9uIHdpdGggcHJvYmFiaWxpdHkgb2YgMS9uIG9uIGV2ZXJ5IG9ic2VydmF0aW9uLiAKICAgIC0gVGhlIGVtcGlyaWNhbCBjdW11bGF0aXZlIGRpc3RyaWJ1dGlvbiBmdW5jdGlvbiB0aGVuIGJlY29tZXMgCiAgICAkJEVDREYoeCkgPSBcc3VtXGxpbWl0c197eF9pIFxsZXEgeH0gXGZyYWN7MX17bn0gPSBcZnJhY3tcIyAoeF9pIFxsZXEgeCl9e259JCQKICAgIApgYGB7cn0KZmVtIDwtIE5IQU5FUyAlPiUgZmlsdGVyKEdlbmRlcj09ImZlbWFsZSImIWlzLm5hKERpcmVjdENob2wpKQpmZW0gJT4lIApnZ3Bsb3QoYWVzKHg9RGlyZWN0Q2hvbCkpICsgCnN0YXRfZWNkZigpCmBgYAoKICAtIFdlIGFsc28gaWxsdXN0cmF0ZSB0aGlzIGZvciBhIHNhbXBsZSB3aXRoIHNhbXBsZSBzaXplIDEwCiAgICAKYGBge3J9CnNldC5zZWVkKDEpCmZlbTEwPC0gTkhBTkVTICU+JSBmaWx0ZXIoR2VuZGVyPT0iZmVtYWxlIiYhaXMubmEoRGlyZWN0Q2hvbCkpICU+JSBzYW1wbGVfbihzaXplPTEwKSAKZmVtMTAgJT4lIGdncGxvdChhZXMoeD1EaXJlY3RDaG9sKSkgKyAKc3RhdF9lY2RmKCkKYGBgCgotLS0KCiMjIE5vcm1hbCBhcHByb3hpbWF0aW9uCgotIEluIHRoZSBpbnRyb2R1Y3Rpb24gd2UgaGF2ZSBzZWVuIHRoYXQgdGhlIGxvZyB0cmFuc2Zvcm1lZCBkaXJlY3QgY2hvbGVzdGVyb2wgbGV2ZWxzIGhhZCBhIG5pY2UgYmVsbCBzaGFwZS4gCgpgYGB7cn0KICBmZW0gJT4lIGdncGxvdChhZXMoeD1EaXJlY3RDaG9sJT4lbG9nMikpKwogIGdlb21faGlzdG9ncmFtKGFlcyh5PS4uZGVuc2l0eS4uLCBmaWxsPS4uY291bnQuLikpICsKICB4bGFiKCJEaXJlY3QgQ2hvbGVzdGVyb2wgKGxvZzIpIikgKwogIHN0YXRfZnVuY3Rpb24oZnVuPWRub3JtLGNvbG9yPSJyZWQiLGFyZ3M9bGlzdChtZWFuPW1lYW4oZmVtJERpcmVjdENob2wlPiVsb2cyKSwgc2Q9c2QoZmVtJERpcmVjdENob2wlPiVsb2cyKSkpCmBgYAoKLSBXZSBjYW4gbm93IGFwcHJveGltYXRlIHRoZSBkaXN0cmlidXRpb24gb2YgbG9nMiB0cmFuc2Zvcm1lZCBkaXJlY3QgY2hvbGVzdGVyb2wgbGV2ZWxzIHVzaW5nIGEgbm9ybWFsIGRpc3RyaWJ1dGlvbi4gCgotIFdlIG9ubHkgaGF2ZSB0byBlc3RpbWF0ZSB0d28gcGFyYW1ldGVyczogdGhlIG1lYW4gYW5kIHRoZSB2YXJpYW5jZS4gV2UgY2FuIGRvIHRoaXMgYmFzZWQgb24gdGhlIHNhbXBsZSBtZWFuICgkXGJhciB4JCkgYW5kIHNhbXBsZSB2YXJpYW5jZSAoJHNeMiQpIG9yIHNhbXBsZSBzdGFuZGFyZCBkZXZpYXRpb24gKCRzJCkuIAoKCmBgYHtyfQp4QmFyPC1tZWFuKGZlbSREaXJlY3RDaG9sJT4lbG9nMikKc2RCYXI8LXNkKGZlbSREaXJlY3RDaG9sJT4lbG9nMikKeEJhcgpzZEJhcgpgYGAKCgotIFdlIGNhbiBkbyB0aGUgc2FtZSB0aGluZyBmb3IgdGhlIHNtYWxsIHNhbXBsZSB3aXRoIDEwIHdvbWVuLgoKYGBge3J9CiAgZmVtMTAgJT4lIGdncGxvdChhZXMoeD1EaXJlY3RDaG9sJT4lbG9nMikpKwogIGdlb21faGlzdG9ncmFtKGFlcyh5PS4uZGVuc2l0eS4uLCBmaWxsPS4uY291bnQuLiksYmlucz0xMCkgKwogIHhsYWIoIkRpcmVjdCBDaG9sZXN0ZXJvbCAobG9nMikiKSArCiAgc3RhdF9mdW5jdGlvbihmdW49ZG5vcm0sY29sb3I9InJlZCIsYXJncz1saXN0KG1lYW49bWVhbihmZW0xMCREaXJlY3RDaG9sJT4lbG9nMiksIHNkPXNkKGZlbTEwJERpcmVjdENob2wlPiVsb2cyKSkpICsKICB4bGltKC0yLDIpCmBgYAoKCmBgYHtyfQp4QmFyMTA8LW1lYW4oZmVtMTAkRGlyZWN0Q2hvbCU+JWxvZzIpCnNkQmFyMTA8LXNkKGZlbTEwJERpcmVjdENob2wlPiVsb2cyKQp4QmFyMTAKc2RCYXIxMApgYGAKCi0tLQoKIyMgUmVmZXJlbmNlIGludGVydmFscwoKLSBOb3JtYWwgdmFsdWVzIGZvciB0aGUgY2hvbGVzdGVyb2wgbGV2ZWxzIGluIHRoZSBwb3B1bGF0aW9uIGNhbiBiZSBjYWxjdWxhdGVkIHVzaW5nIGEgcmVmZXJlbmNlIGludGVydmFsLiBUeXBpY2FsbHkgYSA5NSUgcmVmZXJlbmNlIGludGVydmFsIGlzIHVzZWQsIHNvIHRoYXQgOTUlIG9mIHRoZSBzdWJqZWN0cyBpbiB0aGUgcG9wdWxhdGlvbiBhcmUgZXhwZWN0ZWQgdG8gaGF2ZSBhIHZhbHVlIGZvciB0aGUgY2hhcmFjdGVyaXN0aWMgdGhhdCBmYWxscyBpbnRvIHRoZSByZWZlcmVuY2UgaW50ZXJ2YWwuIAoKLSBXZSBjYW4gZG8gdGhpcyBiYXNlZCBvbiB0aGUgZW1waXJpY2FsIGRpc3RyaWJ1dGlvbiB1c2luZyB0aGUgcXVhbnRpbGUgZnVuY3Rpb24uIFdlIG5lZWQgdG8gY2FsY3VsYXRlIHRoZSBxdWFudGlsZXMgJFxoYXR7Rn0oeF97Mi41XCV9KT0wLjAyNSQgYW5kICRcaGF0e0Z9KHhfezk3LjVcJX0pPTAuOTc1JCBzbyB0aGF0IDk1JSBvZiB0aGUgdmFsdWVzIGFyZSBsb2NhdGVkIGluIHRoZSBpbnRlcnZhbCBbJHhfezIuNVwlfSQsICR4X3s5Ny41XCV9JF0gLiAKCi0gTGFyZ2Ugc2FtcGxlCgpgYGB7cn0KcXVhbnRpbGUoZmVtJERpcmVjdENob2wscHJvYj1jKDAuMDI1LDAuOTc1KSkKYGBgCgotIFNvIGJhc2VkIG9uIHRoZSBsYXJnZSBzYW1wbGUsIHdlIGVzdGltYXRlIHRoYXQgOTUlIG9mIHRoZSBmZW1hbGVzIGluIHRoZSBwb3B1bGF0aW9uIGhhdmUgYSBkaXJlY3QgY2hvbGVzdGVyb2wgbGV2ZWwgaW4gdGhlIGludGVydmFsIFtgciBxdWFudGlsZShmZW0kRGlyZWN0Q2hvbCxwcm9iPWMoMC4wMjUsMC45NzUpKWBdLiAKCi0gU21hbGwgc2FtcGxlCgpgYGB7cn0KcXVhbnRpbGUoZmVtMTAkRGlyZWN0Q2hvbCxwcm9iPWMoMC4wMjUsMC45NzUpKQpgYGAgCiAgICAKLSBOb3RlLCB0aGF0IHRoaXMgZXN0aW1hdGUgaXMgdmVyeSBjcnVkZS4gSW4gdGhlIHNtYWxsIHNhbXBsZSwgIFdlIGRvIG5vdCBoYXZlIGVub3VnaCBvYnNlcnZhdGlvbnMgdG8gaGF2ZSBhIGdvb2QgYXBwcm94aW1hdGlvbiBvZiB0aGUgZXh0cmVtZSBxdWFudGlsZXMuIAogICAgCiMjIyBOb3JtYWwgYXBwcm94aW1hdGlvbgoKLSBXZSBjYW4gdXNlIHRoZSBmdW5jdGlvbiBxbm9ybSB0byBjYWxjdWxhdGUgcXVhbnRpbGVzIGZyb20gdGhlIG5vcm1hbCBkaXN0cmlidXRpb24uIAoKLSBXZSBhbHNvIGtub3cgdGhhdCBhIDk1JSByZWZlcmVuY2UgaW50ZXJ2YWwgaXMgbG9jYXRlZCByb3VnbHkgaW4gdHdvIHN0YW5kYXJkIGRldmlhdGlvbnMgYXJvdW5kIHRoZSBtZWFuLiAKCi0gV2Ugd2lsbCBoYXZlIHRvIHVzZSB0aGUgZnVuY3Rpb24gYDJeYCB0byB0cmFuc2Zvcm0gdGhlIHJlc3VsdCBiYWNrIHRvIHRoZSBkaXJlY3QgY2hvbGVzdGVyb2wgZG9tYWluLiAKCi0gTGFyZ2Ugc2FtcGxlCmBgYHtyfQpxbm9ybSgwLjAyNSxtZWFuPXhCYXIsc2Q9c2RCYXIpICU+JSAyXi4KcW5vcm0oMC45NzUsbWVhbj14QmFyLHNkPXNkQmFyKSAlPiUgMl4uCjJeKHhCYXIgLSAyICogc2RCYXIpCjJeKHhCYXIgKyAyICogc2RCYXIpCmBgYAogICAgICAgIAotIFNtYWxsIHNhbXBsZQpgYGB7cn0KcW5vcm0oMC4wMjUsbWVhbj14QmFyMTAsc2Q9c2RCYXIxMCkgJT4lIDJeLgpxbm9ybSgwLjk3NSxtZWFuPXhCYXIxMCxzZD1zZEJhcjEwKSAlPiUgMl4uCjJeKHhCYXIxMCAtIDIgKiBzZEJhcjEwKQoyXih4QmFyMTAgKyAyICogc2RCYXIxMCkKYGBgCgotLS0KCiMjIENvbmNsdXNpb25zIAoKLSBGb3IgdGhlIGxhcmdlIHNhbXBsZSwgdGhlIGVtcGlyaWNhbCBkaXN0cmlidXRpb24gKHF1YW50aWxlIGZ1bmN0aW9uKSBhbmQgdGhlIG5vcm1hbCBhcHByb3hpbWF0aW9uIGdpdmVzIHVzIGFwcHJveGltYXRlbHkgdGhlIHNhbWUgcmVzdWx0LgoKLSBGb3IgdGhlIHNtYWxsIHNhbXBsZSwgaG93ZXZlciwgdGhlIG5vcm1hbCBhcHByb3hpbWF0aW9uIHdvcmtzIG11Y2ggYmV0dGVyIHRoYW4gdGhlIG9uZSBiYXNlZCBvbiB0aGUgZW1waXJpY2FsIGRpc3RyaWJ1dGlvbi4gCgogICAgLSBUaGlzIGlzIGJlY2F1c2Ugd2UgYXJlIGxvb2tpbmcgYXQgZXh0cmVtZSBxdWFudGlsZXMgMi41JSBhbmQgOTcuNSUuIAogICAgLSBJbmRlZWQsIHdlIGhhdmUgdmVyeSBmZXcgb2JzZXJ2YXRpb25zIGF0IG91ciBkaXNwb3NhbCBpbiB0aGUgc21hbGwgc2FtcGxlIHRvIGVzdGltYXRlIHRoZXNlIHF1YW50aWxlcyBkaXJlY3RseSBmcm9tIHRoZSBvYnNlcnZhdGlvbnMuCiAgICAtIFdpdGggdGhlIG5vcm1hbCBhcHByb3hpbWF0aW9uIHdlIGNhbiB1c2UgYWxsIHRoZSBkYXRhIHRvIGVzdGltYXRlIHRoZSBtZWFuIGFuZCB0aGUgdmFyaWFuY2UuIFNvIGlmIHRoZSBub3JtYWwgYXNzdW1wdGlvbiBob2xkcywgd2UgZ2V0IGJldHRlciBlc3RpbWF0ZXMgZm9yIHRoZXNlIGV4dHJlbWUgcXVhbnRpbGVzLiAKCi0tLQoKIyBTdGF0aXN0aWNzCgotIEZvcm11bGEgd2lsbCBiZSB1c2VkIHRvIGVzdGltYXRlIHRoZSBwYXJhbWV0ZXJzIG9mIGEgZGlzdHJpYnV0aW9uIGluIHRoZSBwb3B1bGF0aW9uIGJhc2VkIG9uIHRoZSBzYW1wbGUuIFdlIGNhbGwgdGhlc2Ugc3RhdGlzdGljcyBvciBlc3RpbWF0b3JzLiAKCi0gVGhlIG51bWVyaWMgcmVzdWx0IG9idGFpbmVkIGJ5IGV2YWx1YXRpbmcgdGhlc2UgZm9ybXVsYSBhcmUgYWxzbyBjYWxsZWQgc3RhdGlzdGljcyBvciBlc3RpbWF0ZXMuIAoKLSBSZXNlYXJjaGVyIHdhbnQgdG8ga25vd24gdGhlIHVua25vd24gcGFyYW1ldGVycyBmcm9tIHRoZSBwb3B1bGF0aW9uIGFuZCB3aWxsIHRodXMgZXN0aW1hdGUgdGhlbSB1c2luZyB0aGUgc3RhdGlzdGljcyBvYnNlcnZlZCBvciBjYWxjdWxhdGVkIGJhc2VkIG9uIHRoZSBzYW1wbGUgCgotIEJlY2F1c2Ugd2UgY2FsY3VsYXRlIHRoZSBzdGF0aXN0aWNzIGJhc2VkIG9uIHRoZSBvYnNlcnZhdGlvbnMgaW4gdGhlIHNhbXBsZSwgdGhleSB3aWxsIGFsc28gdmFyeSBmcm9tIHNhbXBsZSB0byBzYW1wbGUgYW5kIGFyZSByYW5kb20gdmFyaWFibGVzIGFuZCB3ZSBkZW5vdGUgdGhlbSB3aXRoIGNhcGl0YWwgbGV0dGVycyAoZS5nLiAkXGJhciBYJCBmb3IgdGhlIHNhbXBsZSBtZWFuIGFuZCAkU14yJCBmb3IgdGhlIHNhbXBsZSB2YXJpYW5jZSkuIAoKLSBTbyB3aGVuIHdlIGFuYWx5c2UgZGF0YSwgd2UgaGF2ZSB0byByZWFzb24gb24gaG93IHRoZSBzdGF0aXN0aWNzIG9mIGludGVyZXN0IHdpbGwgdmFyeSBmcm9tIHNhbXBsZSB0byBzYW1wbGUuIAoKLSBXaGVuIHRoZSBzdGF0aXN0aWNzIHJlZmVyIHRvIGEgbnVtZXJpYyB2YWx1ZSByZWFsaXNlZCBpbiBhIHBhcnRpY3VsYXIgc2FtcGxlLCB3ZSB3aWxsIHVzZSBhIHNtYWxsIGxldHRlcjogJFxiYXIgeCQgYW5kICRzXjIkLgoKLS0tCgojIENvbnZlbnRpb24KCi0gKipQb3B1bGF0aW9uIHBhcmFtZXRlcnMqKiAgYXJlIGZpeGVkIGJ1dCB1bmtub3duIGFuZCB3ZSB3aWxsIGRlbm90ZSB0aGVtIHdpdGggJFxyaWdodGFycm93JCAqKkdyZWVrIHN5bWJvbHMqKi4KCi0gKipTdGF0aXN0aWNzKiogdGhhdCB3ZSB1c2UgdG8gZXN0aW1hdGUgdW5rbm93biBwYXJhbWV0ZXJzIGJhc2VkIG9uIHRoZSBzYW1wbGUgYXJlIGRlbm90ZWQgd2l0aCAqKmxldHRlcnMqKiBhcmUgd2l0aCBhIGhhdC4gCgotIGUuZy4gZm9yIG5vcm1hbCBkaXN0cmlidXRpb24KCnwgUG9wdWxhdGlvbiB8IFNhbXBsZXwKfCA6LS0tOiB8IDotLS06IHwKfCAkXG11JCB8ICRcYmFyIFgkIG9yICRcaGF0IFxtdSQgfAp8ICRcc2lnbWFeMiQgfCAkU14yJCBvciAkXGhhdCBcc2lnbWEkfAogICAgICAgIAogICAgICAKCg==